Onderzoeksmethoden 2/het werk/2008-9/Groep01
De relatie tussen publicatie van privacygevoelige gegevens op de sociale netwerksite Hyves en het opleidingsniveau/volwassenheid
Inhoud
Praktische informatie
Informatieoverzicht groep 1
Onderzoeksmethode: tekstanalyse
| Gebruikersnaam | Studentnumer | |
|---|---|---|
| Roy de Vries | s0719781 | roydevries@xs4all.nl |
| Desi van der Burgt | s0722693 | info@desivanderburgt.nl |
| Kevin Kluijtmans | s0717703 | kevin@kevinkluijtmans.nl |
| Herman Dammers | s0652601 | h.dammers@student.ru.nl |
Probleemstelling
Sociale netwerkingsites, zoals de gratis (in ieder geval de basisdienst) en populaire Nederlandse profielensite Hyves, bieden onder andere de mogelijkheid om digitaal berichten te plaatsen bij personen (gebruikers) in je (persoonlijke) netwerk en te vertellen over wie je bent en wat je voorkeuren zijn. Ook kunnen gebruikers bijdragen aan specifieke gemeenschappen binnen het grotere sociale netwerk. Dergelijke mogelijkheden maken het zeer laagdrempelig om privacygevoelige informatie te publiceren, waardoor dergelijke informatie bekend kan raken bij derden.
Bij ons bestaat een vermoeden dat er een verband bestaat tussen de publicatie van privacygevoelige gegevens op de sociale netwerksite Hyves en het opleidingsniveau of de leeftijd van gebruikers. Binnen de wetenschappelijke wereld zijn nog geen gegevens beschikbaar waarmee de vraag beantwoord kan worden of dit daadwerkelijk het geval is. Het eerder opgetekende vermoeden hebben wij geformaliseerd in de volgende centrale onderzoeksvraag:
- Wordt de hoeveelheid gepubliceerde privacygevoelige informatie die een Nederlands persoon publiceert op de profielensite Hyves in krabbels en het profiel bepaald door het opleidingsniveau of volwassenheid?
Volwassenheid betekent in deze context dat een persoon volwassen is, wij hanteren hiervoor de leeftijdsgrens 21 jaar of ouder.
Verantwoording
In de westerse wereld wordt veel belang gehecht aan privacy, denk bijvoorbeeld aan het bestaan van speciale organen als het College bescherming persoonsgevens (CBP), Der Bundesbeauftragte für den Datenschutz und die Informationsfreiheit (BfDI), Comissão Nacional de Protecção de Dados (CNPD), etc. Ook leiden wetsvoorstellen zoals de Amerikaanse Patriot Act of gebeurtenissen zoals het aantonen van Stichting “Wij vertrouwen stemcomputers niet” in eind 2006 dat de in Nederland gebruikte stemcomputers onveilig en slecht controleerbaar zijn, tot veel discussie in de samenleving. Ook konden we onlangs nog in de media vernemen dat in Duitsland een massaal protest heeft plaatsgevonden van verontruste mensen welke vrezen voor hun privacy. Bij sommige mensen in deze samenleving lijken dergelijke gebeurtenissen dus een onbehaaglijk en bang gevoel te veroorzaken, en wordt de vraag gesteld of onze privacy te veel wordt aangetast. Ook (of misschien toch) lijken wij, individuen, zelf anders om te gaan met onze privacy als in het verleden. Zo werd de "De Big Brother Award 2007" in de categorie personen, een prijs voor die organisatie of die persoon welke de privacy het meeste in gevaar brengt, toegewezen aan onszelf ... de Nederlandse burger.
Uit een analyse van beschikbare onderzoeksresultaten blijkt dat er weinig inzicht is in het verband tussen persoonseigenschappen en het publiceren van privacygevoelige informatie. Gezien de waarde welke wij, als westerse samenleving, toekennen aan privacy is het belangrijk dat er al dan niet een bevestiging komt of dergelijke verbanden bestaan. Een van de subonderwerpen binnen dit aandachtsgebied is het al dan niet bestaan van dergelijke verbanden in de context van de zeer populaire en nog steeds groeiende Nederlandse profielensite Hyves.
Daarnaast zijn de resultaten ook direct praktisch toepasbaar. Zo kan Hyves bijvoorbeeld inspelen op het gedrag van haar gebruikers, wanneer een verband wordt aangetroffen tussen opleidingsniveau en/of volwassenheid en privacy-bedreigend gedrag. Dit door bijvoorbeeld gerichte waarschuwingen en actieve beperkingen van de mogelijkheden om dergelijke informatie te publiceren.
Theoretisch kader
Het onderzoek beslaat een aantal verschillende subvakgebieden van onderzoek. Onderstaand is door middel van stapsgewijze inperking inzicht gegeven in deze deelgebieden:
- Sociale wetenschappen
- Gedragswetenschappen
- Communicatiewetenschap
- Virtuele gemeenschap
- Sociale netwerken
- Sociaal netwerk vraagstuk: GEBRUIKERS EN DE OMGANG MET PERSOONSGEGEVENS
- Sociale netwerken
- Virtuele gemeenschap
- Communicatiewetenschap
- Gedragswetenschappen
Theoretisch model
Op basis van de al reeds eerder opgetekende probleemstelling kunnen we een theoretisch model creëren, zie daartoe figuur 1.
|
|
|
Figuur 1: De variabelen |
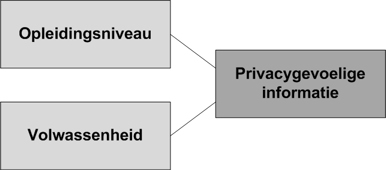
Voor een formele notatie ten aanzien van de in dit model opgetekende variabelen verwijzen we u overigens naar bijlage A.
- Onafhankelijk variabelen:
- 1. Opleidingsniveau
- 2. Volwassenheid
- Afhankelijk variabelen:
- 1. Privacygevoelige informatie
Termen en concepten
- Definitie van opleidingsniveau: het hoogste niveau waarop een persoon een opleiding heeft gevolgd. De persoon hoeft de studie niet succesvol te hebben afgerond. Het is onmogelijk onafgeronde en afgeronde opleidingen te onderscheiden, omdat Hyves hier geen onderscheidt tussen maakt. Ook zal er geen onderscheidt worden gemaakt tussen de schoolvorm waaraan iemand heeft deelgenomen in het middelbaar onderwijs, ook hier omdat Hyves hier geen onderscheidt tussen maakt.
- Definitie van volwassenheid: het aantal gehele jaren dat is verstreken sinds de geboortedatum van de persoon. Als dit 21 jaar of meer is, dan is een persoon volwassen, anders niet.
- Definitie van privacygevoelige informatie (“paraplu begrip”): informatie omtrent persoonsgegevens, lidmaatschap van groepen, contactgegevens, voorkeuren en gebeurtenissen welke direct kunnen worden toegeschreven aan een uniek aanwijsbaar persoon.
Methode
Onderzoeksfunctie
Dit onderzoek kan gekenschetst worden als een verkennend onderzoek. Op basis van een vermoeden zal gezocht worden naar het bestaan van verbanden tussen bepaalde kenmerken (in dit geval volwassenheid en opleidingsniveau) van een specifieke groep personen (gebruikers van Hyves) en gedrag (in dit geval de mate waarin deze groep privacygevoelige informatie publiceert op een social networking-website). Deze informatie is nu nog niet beschikbaar.
Onderzoeksstructuur
Om de centrale onderzoeksvraag te beantwoorden, dienen de volgende deelvragen te worden beantwoord:
- Hoeveel informatie-eenheden worden in de door ons benoemde privacy categorieën gepubliceerd door iedere onderscheidde volwassenheidsgroep?
- Hoeveel informatie-eenheden worden in de door ons benoemde privacy categorieën gepubliceerd door iedere onderscheidde opleidingsgroep?
- Hoe verhouden de aantallen zich tot elkaar als het gaat om de onderscheidde groepen?
De term informatie-eenheden behoeft hierbij een nadere verklaring. Voor het doel van dit onderzoek definiëren wij een informatie-eenheid als relevante informatie, lees informatie welke geclassificeerd kan worden in een van de door ons benoemde categorieën (zie het Empirisch model), bestaande uit een reeks van semantisch samenhangende gegevens. Denk hierbij bijvoorbeeld aan reeks cijfers welke samen een telefoonnummer vormen of een reeks namen van artiesten.
Onderzoeksmodel
Dataverzameling
De brondata zijn afkomstig van de individuele webpagina's (profielpagina's) van de leden van het Hyves netwerk. Op moment t (zie fig. 2) zullen de volgende onderdelen van een tweetal individuele pagina gelezen worden: één 'krabbel' op pagina 'A' (tekstbericht op profielpagina van gebruiker, doorgaans geplaatst door lid van het netwerk van deze gebruiker) en het 'profiel' (persoonsbeschrijving opgesteld door de eigenaar van de profielpagina, bestaat uit een aantal automatisch gegenereerde gegevens, enkele verplichte en enkele vrijwillig toe te voegen velden) van de persoon welke de verzamelde 'krabbel' heeft geplaatst op pagina 'B'.
Leden worden gekozen op basis van de sneeuwbalmethode. Dit betekend dat op de openingspagina van Hyves (www.hyves.nl) willekeurig een profiel wordt gekozen, om vervolgens, na het verzamelen van de vereiste data, uit het netwerk van deze gebruiker een willekeurig ander lid te kiezen. Dit proces zal zich herhalen totdat er voldoende informatie is verzameld. Gezien dat we de Small world experiments van Stanley Milgram weten dat personen via korte lijnen in netwerken verbonden zijn, kunnen we er vanuit gaan dat dit selectieprocedé een voldoende willekeurige selectie van gebruikers oplevert.
Voordat een 'profiel' en een 'krabbel' kunnen worden meegenomen in de analyse moet worden vastgesteld of de leeftijd en het opleidingsniveau kunnen worden opgetekend. Dit vereist dat deze gegevens vermeldt zijn in het 'profiel' en dat deze informatie voor ons zichtbaar is.
|
|
|
Figuur 2: Het onderzoeksdesign |

Verwerking
De verzamelde teksten zullen in het ASCII formaat beschikbaar zijn voor een nadere verwerking. Deze teksten zullen gecodeerd worden op basis van datgene wat opgetekend is in het empirisch model. De codering zelf zal geschieden via een tweeërlei manieren, namelijk:
- geautomatiseerde tagging;
- handmatige tagging;
Een nadere toelichting ten aanzien van de handeling van het 'taggen'.
Geautomatiseerde tagging:
De voordelen van geautomatiseerde tagging zijn onder andere efficiëntie en eenvoud in gebruik. In dit onderzoek zal de computer dan ook dienen als een waardige aanvulling op de handmatige tekstanalyse. Middels een applicatie bestaande uit webpagina's (PHP, met gebruik van reguliere expressies) wordt op een geautomatiseerde wijze privacygevoelige informatie geclassificeerd, 'getagt'. Dit biedt de mogelijkheid om op een snelle en daarmee kostenbesparende wijze eenvoudig privacygevoelige gegevens zoals telefoonnummers, e-mail adressen, postcodes, etc. te vinden en te classificeren. De gevonden gegevens zijn tevens direct beschikbaar voor verdere verwerking.
Middels een korte schets van de applicatie lichten wij dit proces verder toe:
1. In de eerste stap wordt de geselecteerde informatie ('profiel', 'krabbel') ingevoerd in de applicatie, de gebruiker plakt hiervoor de vereiste tekst in een invoerveld. Een record van deze invoer wordt opgeslagen in de database van de applicatie.
2. In de tweede stap wordt met behulp van reguliere expressies gezocht naar bepaalde categorieën van gegevens welke automatisch kunnen worden herkent. Deze gegevens worden vervolgens automatisch gecodeerd, dit wil concreet zeggen, de betrokken data (karakters) worden 'gevangen' tussen 'tags'. Een voorbeeld: [telefoonnummer]040-1234567[/telefoonnummer].
3. In de derde stap voegt de menselijke gebruiker aanvullende tags toe. Zie ook Handmatige tagging hieronder.
4. De laatste stap houdt in dat er aan de gebruiker geactualiseerde en relevante statistische data, gebaseerd op de invoer van de gebruiker, wordt getoond.
Handmatige tagging:
De computer biedt niet altijd de mogelijkheid om de semantiek van de verzamelde ASCII data (in dit geval de Hyves profielen) (eenvoudig) "te vangen". Daarom zullen bepaalde tekst items met de hand dienen te worden gecategoriseerd, oftewel getagt, naar de groep van privacygevoelige informatie waar de data toe behoort. Dit proces van handmatig taggen is geïntegreerd in de applicatie zoals eerder hierboven beschreven is. De gebruiker geeft in de derde stap van het proces, zoals eerder beschreven, middels tags (bijv. [e-mail]...[/e-mail]) aan welke karakters tezamen een informatie-eenheid vormen in de aangewezen categorie.
Analyse
Na het coderen rest slechts nog het "tellen", de kwalitatieve inhoudsanalyse leidt tot een tekst welke wel of niet gelabeld is met een bepaalde categorie. Bijvoorbeeld er wordt geen leeftijd vermeld in de tekst, dit leidt er toe dat deze tekst niet gelabeled zal worden met de categorie "Privacygevoelige informatie" - "Persoonlijke informatie" - "Leeftijd". Het gaat dus om de aangelegenheid van het benoemen van (nominaal). Wanneer een categorie echter wel benoemd kan worden, los van de hoeveelheid vermeldingen, zal dit gezien worden als het vrijgeven van privacygevoelige informatie. Het vrijgeven van deze informatie wordt bestraft met de puntoptelling van één punt, waarbij elke persoon start met een nul score. Afhankelijk van de classificatie van de gevonden data wordt deze puntoptelling vermenigvuldigd met een wegingsfactor. Sommige categorieën worden beschouwd als zijnde privacygevoeliger, dit vertaalt zich naar de volgende situatie:
- zeer hoog privacygevoelige categorie - wegingsfactor hoog (punt x 3);
- hoog privacygevoelige categorie - wegingsfactor gemiddeld (punt x 2);
- enigzins privacygevoelige categorie - wegingsfactor laag (punt x 1);
De persoon met de hoogste score is op deze wijze dus ook de persoon die het meeste privacygevoelige informatie heeft vrijgegeven.
Domein
Theoretische populatie:
- Onderzoekselementen: het Universum
- M: Alle mensen die als lid ingeschreven staan of hebben gestaan bij de Nederlandse profielensite Hyves vanaf de oprichting in 2004 van wie de individuele pagina toegankelijk is.
Operationele populatie:
- Onderzoekselementen: de operationele populatie
- M: 7.470.000 mensen die als lid ingeschreven staan of hebben gestaan bij de Nederlandse profielensite Hyves vanaf de oprichting in 2004 van wie de individuele pagina toegankelijk is.
Op basis van het beschikbare onderzoeksbudget dient er helaas een inperking plaats te vinden van de operationele populatie. De steekproefgrootte n is op basis van een gewenst betrouwbaarheidspercentage van 55%, een steekproef marge van 5% en een spreiding van 50%: 58. Concreet betekent dit, dat de gegevens van 58 leden van het Hyves netwerk onderzocht zullen worden op basis van de in dit document vastgestelde kenmerken. De basismethode van de steekproef trekking zal in dit geval een selecte steekproef (een 'judgement sample') zijn. De eenheden zullen dus niet op toevalsbasis uit de populatie getrokken worden en er is niet sprake van een gelijke kans, maar de selectie vindt plaats op basis van het oordeel van de onderzoeker. Het voordeel van deze steekproefmethode: snel, eenvoudig, acceptabel om een eerste indruk te krijgen. Het nadeel van deze methode van onderzoek is echter aanzienlijk te noemen: weinig betrouwbaar en geen representatieve steekproef.
Steekproef:
- Onderzoekselementen: deel van de operationele populatie - steekproef
- M: 58 mensen die als lid ingeschreven staan of hebben gestaan bij de Nederlandse profielensite Hyves vanaf de oprichting in 2004, van wie de individuele pagina toegankelijk is en van wie leeftijd en opleidingsniveau bepaalt kunnen worden.
Empirisch model
Om vast te stellen wat nu daadwerkelijk privacygevoelige informatie is, hebben we gebruik gemaakt van de privacy definitie van Wikipedia (2008).
"Privacy is een afweerrecht dat de persoonlijke levenssfeer beschermt. Het recht op privacy wordt ook wel omschreven als het recht om met rust te worden gelaten (The right to be left alone volgens de definitie van Warren & Brandeis, die de eerste juridisch getinte definitie van privacy gaven). Privacy is een ruim begrip: het gaat onder meer om de bescherming van persoonsgegevens, de bescherming van het eigen lichaam en van de eigen woning, de bescherming van familie- en gezinsleven, en het recht vertrouwelijk te communiceren via, brief, telefoon, e-mail en dergelijke. Privacy betekent dat men dingen kan doen zonder dat de buitenwereld daar inbreuk op maakt of zelfs weet van heeft. Privacy heeft met verschillende disciplines te maken, zoals ethiek, informatiekunde en rechtsgeleerdheid."
In de onderstaande tabel treft u de variabelen aan die onder andere iets zeggen over wie de persoon is, waar de persoon is, hoe de persoon is en wat zijn/haar voorkeur is. De mate waarin informatie vrijgegeven wordt betreffende deze variabelen, geeft inzicht in hoe er omgegaan wordt met privacygevoelige informatie en kan zelfs leiden tot een voorzichtige verklaring ten aanzien van de bevindingen. Tevens is in de vierde kolom de wegingsfactor opgetekend, die factor welke eerder vermeldt is in het onderzoeksmodel.
| Theoretische Variabelen | Indicatoren | Empirische Variabelen | Handmatig/automatisch | Tag | Wegingsfactor |
|---|---|---|---|---|---|
| Privacygevoelige informatie | Persoonlijke informatie | ||||
| Voornaam | Hand | [front_name]..[/front_name] | laag | ||
| Achternaam | Hand | [back_name]..[/back_name] | laag | ||
| Adres | Hand | [address]..[/address] | hoog | ||
| Postcode | Auto | [zip]..[/zip] | gemiddeld | ||
| Woonplaats | Hand | [residence]..[/residence] | gemiddeld | ||
| Tel. Nr. | Hand | [phone]..[/phone] | hoog | ||
| Auto | [mail]..[/mail] | gemiddeld | |||
| Leeftijd | Hand | [age]..[/age] | gemiddeld | ||
| Burgerlijke staat | Hand | [civil_state]..[/civil_state] | laag | ||
| Religie | Hand | [religion]..[/religion] | hoog | ||
| Woonsituatie | Hand | [living_sit]..[/living_sit] | laag | ||
| Geslacht | Hand | [gender]..[/gender] | laag | ||
| Talen | Hand | [language]..[/language] | laag | ||
| Website | Hand | [website]..[/website] | laag | ||
| Scholen | Hand | [school]..[/school] | laag | ||
| Bedrijven | Hand | [company]..[/company] | laag | ||
| Verenigingen | Hand | [association]..[/association] | laag | ||
| Persoonlijke voorkeuren | |||||
| Merken | Hand | [brand]..[/brand] | laag | ||
| Boeken/tijdschriften | Hand | [book]..[/book] | laag | ||
| Audio | Hand | [audio]..[/audio] | laag | ||
| Video | Hand | [video]..[/video] | laag | ||
| Eten | Hand | [food]..[/food] | laag | ||
| Hangouts | Hand | [hangout]..[/hangout] | gemiddeld | ||
| Reizen | Hand | [travel]..[/travel] | gemiddeld | ||
| Sport | Hand | [sports]..[/sports] | gemiddeld | ||
| Spots | Hand | [spots]..[/spots] | gemiddeld | ||
| Gebeurtenissen | |||||
| Feest | Hand | [party]..[/party] | laag | ||
| Familiegebeurtenis | Hand | [fam_hap]..[/fam_hap] | gemiddeld | ||
| Verjaardag | Hand | [anniversary]..[/anniversary] | gemiddeld | ||
| Stemmingsindicatie | Hand | [vote]..[/vote] | gemiddeld | ||
| Opleidingsniveau | Opleidingsniveau | ||||
| Volwassenheid | Volwassenheid |
Tabel 1: Het empirisch model
Tijd- en faseringsschema
Het onderzoek zal plaatsvinden gedurende de periode oktober 2008 - december 2008 aan de Radboud Universiteit te Nijmegen door die personen welke vermeld worden in het informatieoverzicht op deze pagina. Er is gekozen voor de volgende globale tijdsfasering:
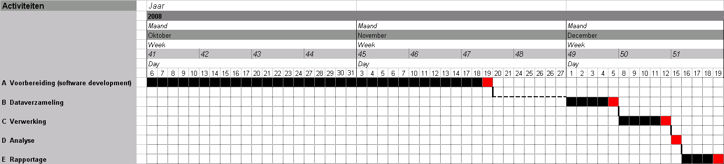
Tabel 2: Globale tijdsfasering
Deze fasering resulteert in een doorlooptijd van 55 werkdagen, oftewel 11 weken. Gedurende de hierboven opgetekende fasen zullen de volgende activiteiten worden uitgevoerd:
| Fase | Activiteiten | Tijdsduur (uren) | Looptijd (dagen) |
| A Voorbereiding (software development) |
|
100 |
33 |
| B Dataverzameling |
|
15 |
05 |
C Verwerking |
|
50 |
05 |
| D Analyse |
|
01 |
01 |
| E Rapportage |
|
06 |
04 |
| Totaal | 172 |
48 |
Tabel 3: Onderzoeksactiviteiten
Literatuur
| Wikipedia (2008). Privacy. Retrieved oktober 8, 2008, from Wikimedia Foundation, Inc. Website: |
Bijlage A: Theoretisch model
Variabelen:
- Privacygevoelige informatie: M -> <construct>.
De privacygevoelige informatie betreffende persoon M.
Soort: afhankelijk;
Meetniveau: nominaal;
- Opleidingsniveau: M -> Opleidingsniveau.
Het opleidingsniveau van persoon M.
Soort: onafhankelijk;
Meetniveau: nominaal;
- Opleidingsniveau: M -> Volwassenheid.
De volwassenheid van persoon M.
Soort: onafhankelijk;
Meetniveau: nominaal;
Bijlage B: Tussenmodel
Indicatoren voor de variabelen:
- Privacygevoelige informatie: M -> Persoonlijke informatie <indicator>.
De persoonlijke informatie van persoon M.
Soort: afhankelijk;
- Privacygevoelige informatie: M -> Persoonlijke voorkeuren <indicator>.
De persoonlijke voorkeur van persoon M.
Soort: afhankelijk;
- Privacygevoelige informatie: M -> Gebeurtenissen <indicator>.
De gebeurtenissen waarin persoon M een rol speelde.
Soort: afhankelijk;
Bijlage C: Empirisch model
Variabelen:
- Persoonlijke informatie <indicator>: M -> Voornaam{voornaam}.
De voornaam van persoon M.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke informatie <indicator>: M -> Achternaam{achternaam}.
De achternaam van persoon M.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke informatie <indicator>: M -> Adres{adres}.
Het adres van persoon M.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke informatie <indicator>: M -> Postcode{postcode}.
De postcode van persoon M.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke informatie <indicator>: M -> Woonplaats{woonplaats}.
De woonplaats van persoon M.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke informatie <indicator>: M -> Telefoonnummer{telefoonnummer}.
Het telefoonnummer van persoon M.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke informatie <indicator>: M -> E-mail{e-mail}.
Het emailadres van persoon M.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke informatie <indicator>: M -> Leeftijd{leeftijd}.
De leeftijd van persoon M.
Soort: afhankelijk;
Meetniveau: interval;
- Persoonlijke informatie <indicator>: M -> Burgerlijke staat{huwelijkse staat, geregistreerd partnerschap, voogdij, curatelestelling}.
De burgerlijke staat van persoon M.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke informatie <indicator>: M -> Religie{Christendom, Islam, Hindoeïsme, Boeddhisme, Taoïsme, Sikhisme, Jodendom, Bahá'í, Jainisme, Niet-religieus, onbekend}.
Persoon M is een volger van religie x.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke informatie <indicator>: M -> Woonsituatie{getrouwd, samenwonend, alleenstaand}.
De woonsituatie van persoon M.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke informatie <indicator>: M -> Geslacht{man, vrouw}.
Het geslacht van persoon M.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke informatie <indicator>: M -> Taal{taal}.
De taal welke persoon M spreekt.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke informatie <indicator>: M -> Website{website}.
De website welke persoon M bezoekt.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke informatie <indicator>: M -> School{school}.
De school welke door persoon M is opgetekend.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke informatie <indicator>: M -> Bedrijf{bedrijf}.
Het bedrijf welke door persoon M is opgetekend.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke informatie <indicator>: M -> Vereniging{vereniging}.
De vereniging welke door persoon M is opgetekend.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke voorkeuren <indicator>: M -> Merken{merken}.
De merken welke persoon M opgetekend heeft.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke voorkeuren <indicator>: M -> Boeken{boeken}.
De boeken welke persoon M opgetekend heeft.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke voorkeuren <indicator>: M -> Audio{audio}.
De audio welke persoon M opgetekend heeft.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke voorkeuren <indicator>: M -> Video{video}.
De video welke persoon M opgetekend heeft.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke voorkeuren <indicator>: M -> Eten{eten}.
Het eten welke persoon M opgetekend heeft.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke voorkeuren <indicator>: M -> Hangouts{bar, club, restaurant}.
De uitgaansgelegenheid waar M zich wel eens bevindt of een voorkeur voor tentoonspreidt.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke voorkeuren <indicator>: M -> Reizen{reizen}.
Het reizen welke persoon M opgetekend heeft.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke voorkeuren <indicator>: M -> Sport{sport}.
De sporten welke door persoon M opgetekend zijn.
Soort: afhankelijk;
Meetniveau: nominaal;
- Persoonlijke voorkeuren <indicator>: M -> Spots{spot}.
De plaatsen waar persoon M gespot is.
Soort: afhankelijk;
Meetniveau: nominaal;
- Opleidingsniveau: M -> Opleidingsniveau{basisschool, middelbaar onderwijs, MBO, HBO, WO}.
Het opleidingsniveau van persoon M.
Soort: onafhankelijk;
Meetniveau: ordinaal;
- Volwassenheid: M -> Volwassenheid{ja, nee}.
De volwassenheid van persoon M.
Soort: onafhankelijk;
Meetniveau: nominaal;
Relaties:
|
|
|
Figuur 3: Relatie empirisch model |
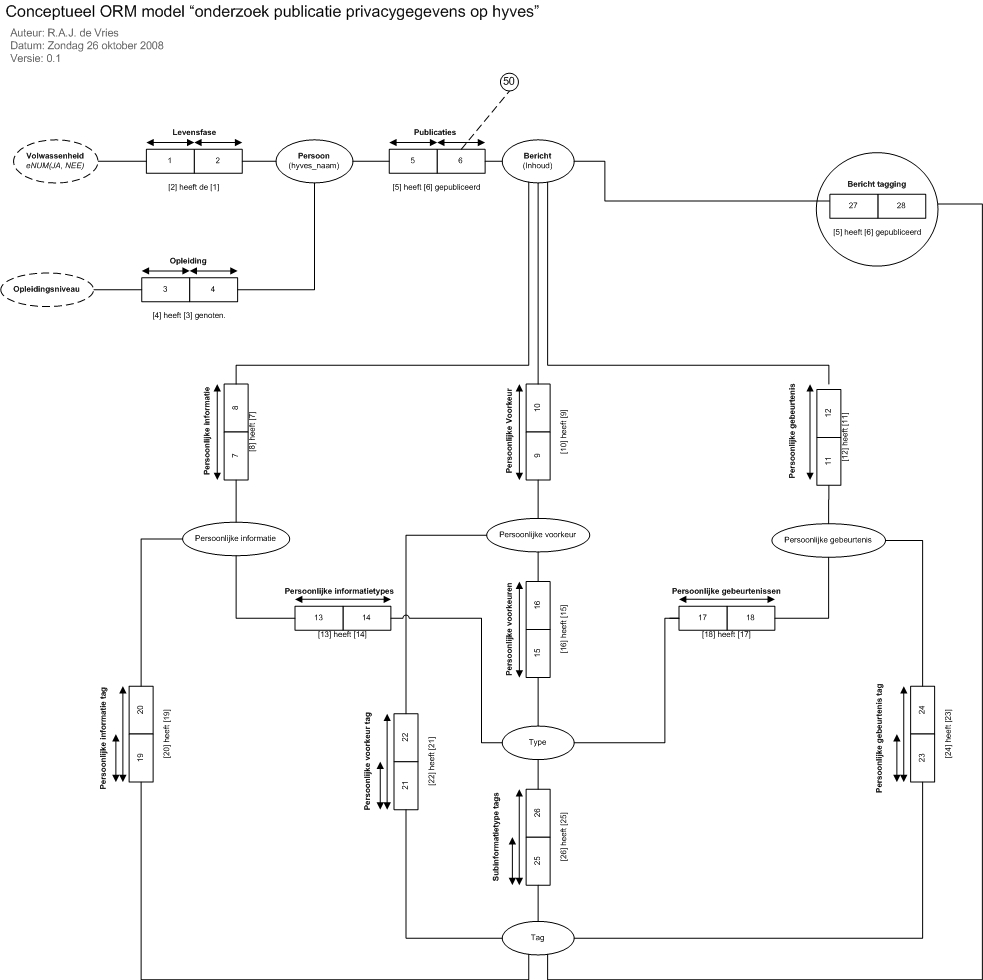
Bijlage D: De bronteksten
De bronteksten zullen beschikbaar worden gesteld via de nu volgende hyperlink: http://www.roydevries.com/ozm/tagging.php .