Onderzoeksmethoden 2/het werk/2007-8/Groep06
Inhoud
Basisgegevens
- Titel
- Tekstanalyse
- Onderzoekers
- Niels van Bokhoven
- Teun Huijbers
Inleiding
Voor het vak onderzoeksmethoden(Vervolg) gegeven door Stijn Hoppenbrouwers hebben wij een experiment uitgevoerd waarbij met behulp van verschillende methodes en technieken informatie hebben verzameld voor wetenschappelijk onderzoek. De keuze bestond uit verschillende methodes namelijk: Tekstanalyse, Interviews, Think Aloud Protocols en Workshops. Wij hebben gekozen voor Tekstanalyse omdat dit met het oog op de thesis ons relevant leek. Ook een reden was om voor deze techniek te kiezen omdat alle andere methoden/technieken uiteindelijke neer komt op tekstanalyse.
In dit rapport beginnen we met het opstellen van de onderzoeksvraag voor het experiment waarop we tekstanalyse op zullen toepassen.
Probleemstelling
In deze paragraaf wordt de probleemstelling voor ons experiment uiteengezet. Als onderzoeksvraag hebben wij het volgende gekozen:
Hoeveel argumenten worden er gebruikt per beslissing als twee personen bezig zijn met het maken van een Entity-relationship model van een Bibliotheek ?
Om deze vraag te kunnen beantwoorden met behulp van tekstanalyse zal als resultaat van het experiment een tekst (log/transcript) nodig zijn. We hebben ervoor gekozen om gebruik te maken van een chatlog. Het experiment zal bestaat uit twee personen die met elkaar communiceren met behulp van een chatbox/chatprogramma. De conversatie zal vervolgens worden opgeslagen in een chatlog en deze zullen wij gaan analyseren met behulp van tekstanalyse technieken.
We zullen gebruik gaan maken van de techniek Discourse analysis. Dit is geschikt voor het analyseren van gesprekken/dialogen en waarbij er onderzoek wordt gedaan naar paren van uitspraken. We zullen ons gaan richten op de argumenten en beslissingen. Hiermee trachten we de onderzoekshypothese te beantwoorden.
Conceptueel model
Hieronder is de gestileerde weergave van het conceptueel model te vinden. Omdat de focus ligt op de hands-on ervaring van het uitvoeren van deze techniek, hebben we gekozen om meteen een gestileerde weergave te maken van het conceptueel model. De uitgebreide versie ervan ontbreekt dus om deze rede.
Onderzoekselementen
S: Studenten
Variabelen
Argumenten: S -> A: {aantal}: Ratio
Beslissingen: S -> B: {aantal}: Ratio
Model: S -> C: {ja, nee}: Nominaal
Relaties
De argumenten die tijdens de conversatie gegeven worden zullen invloed hebben op de beslissingen die genomen zullen worden. Deze beslissingen zullen vervolgens weer invloed hebben op het Entity-relationship model. Daarop hebben wij de volgende relatie gebaseerd.
{kind=link}
Experiment
In deze paragraaf wordt beschreven hoe we aan de data zijn gekomen, hoe we dit hebben vastgelegd en hoe we de data hebben geanalyseerd.
Data verzamelen
We hebben de data verzameld middels een chat programma. Het experiment behelst dat we twee proefpersonen uit de steekproefkader studenten, met behulp van een chat programma een Entity-relationship model laten maken. Als case hebben we gekozen voor een bibliotheek. Hierbij nemen we aan dat de proefpersonen een weten hoe een bibliotheek werkt. De proefpersonen mogen enkel het chat programma gebruiken om te communiceren. Verder is het mogelijk om op een A4 papier te tekenen aangezien dit de communicatie onderling kan verbeteren. Het is toegestaan om de tekeningen uit te wisselen. Echter is het niet de bedoeling dat er via de tekening gecommuniceerd zou worden. Daarom controleren we de tekening en brengen we de tekening naar de andere proefpersoon.
Data Vastleggen
De data die het experiment zal generen wordt middels het chat programma vastgelegd. Het programma wat er gebruikt gaat worden als chat programma zal Windows Live Messenger [1] zijn, ook wel MSN Messenger genoemd. Dit programma bevat een functie om de chatlog op te slaan als een RTF bestand. Zodat de data in een plat tekstbestand beschikbaar is voor de analyse. Daarnaast maakt hij ook een log van de gespreksgeschiedenis.
Data Analyse
De date die we gaan analyseren wordt gedaan met behulp van de techniek tekstanalyse. De methode van tekstanalyse die wij zullen gaan toepassen is de discourse analysis. Bij deze methode gaan worden delen van de chatlog gelabeld met verschillende kleuren. Aangezien het onderzoek is gericht op argumenten en beslissingen gaan we ons daar specifiek op richten. Dus argumenten krijgen in de chatlog de kleur rood en beslissingen de kleur blauw.
Jan
zegt: |
Ik ga voor de kleur rood. | |
Piet
zegt: |
Waarom dan? | |
Jan
zegt: |
Rood is beter zichtbaar op een witte achtergrond vergeleken met geel. | Argument |
Piet
zegt: |
Daar heb je gelijk in, laten we rood nemen. | Beslissing |
Data Rapporteren
De log van de conversatie tussen onze proefpersonen met de daarbij behorende modellen is hier te vinden: 8M:OM2-Groep6 - Chatlog. De log na eerste analyse om onze hoofdvraag te kunnen beantwoorden: 8M:OM2-Groep6 - Chatlog Analyse 1. De log na de tweede analyse om te controleren is of er sprake is van leiderschap tijdens het gesprek: 8M:OM2-Groep6 - Chatlog Analyse 2.
Conclusie
Op basis van de vergaarde data van 8M:OM2-Groep6 - Chatlog Analyse 1 stelt ons in staat om een antwoord te kunnen geven op de hoofdvraag. De vraag luidde:
Hoeveel argumenten worden er gebruikt per beslissing als twee personen bezig zijn met het maken van een Entity-relationship model van een Bibliotheek?
Totaal zijn er tijdens dit gesprek 10 argumenten genoemd waaruit beslissingen uit voort zijn gekomen. Echter als er specifiek gekeken wordt naar de argumenten en beslissingen dan is er te concluderen dat er 4 argumenten geen betrekking hebben op beslissingen die te maken hebben met het bepalen van het model. Dus er zijn 6 argumenten genoemd waaruit 5 beslissingen zijn genomen. Dit resulteerd het volgende antwoord: 6 / 5 = 1.2. Dan zou er dus per beslissing 1.2 argumenten gegeven worden.
Op basis van deze data is dit een antwoord op de onderzoeksvraag. Het experiment is te kleinschalig om de mogelijkheid te bieden om dit te generaliseren. We concluderen dat er te weinig discussie is geweest omtrent het creeeren van het Entity-relationship model. Dit kan verschillende oorzaken hebben. Wij denken dat het domein van de opdracht en de kennis van de personen hiervan de oorzaak zijn. Het domein was achteraf gezien te makkelijk waardoor er geen tot weinig discussie heeft plaatsgevonden. Tevens zou de kennis van de proefpersonen een mogelijke oorzaak kunnen zijn. De proefpersonen beiden wisten hoe ze een Entity-relationship model moesten maken en kende allebei het bibliotheek domein vrij goed.
De data van 8M:OM2-Groep6 - Chatlog Analyse 1 biedt ons dus te weinig om een goede analyse te kunnen maken. Hierdoor hebben we gekozen om de tekst op een andere manier te analyseren. Dit keer met een ander doel. We willen achterhalen of er tijdens het gesprek een proefpersoon een dominante rol voert. Op basis van dit idee is er een tweede onderzoeksvraag opgesteld.
Is er tijdens hetmaken van een Entity-relationship model van een Bibliotheek een testpersoon de leider geweest van het gesprek?
Aan de hand van de nieuwe onderzoeksvraag hebben we de verkregen data opnieuw geanalyseerd. Het resultaat hiervan is te vinden op 8M:OM2-Groep6 - Chatlog Analyse 2. Met behulp van tekstanalyse hebben nu de tekst op een andere manier gelabelled. We zijn gaan zoeken naar vragen, agreements, samenvattingen en voorstellen in de reacties. Iemand die de leider is over een gesprek, zal meer initiatief tonen dus waarschijnlijk ook meer voorstellen en opsommingen / samenvattingen doen in vergelijking met de andere persoon. De wat passievere persoon zal waarschijnlijk meer vragen stellen en vaak akkoord gaan met dingen die voorgesteld worden door de leider. Daarom zijn wij gaan zoeken naar deze 4 soorten van reacties. Deze zullen we gaan tellen en op basis daarvan gaan we een antwoord geven op de vraag Is er tijdens hetmaken van een Entity-relationship model van een Bibliotheek een testpersoon de leider geweest van het gesprek?
Testpersoon
1 (Harry) |
Testpersoon
2 (Jan) |
Totaal |
|
| Reacties | 75 |
52 |
127 |
| Vragen | 9 |
9 |
18 |
| Agreements | 10 |
10 |
20 |
| Samenvattingen | 2 |
1 |
3 |
| Voorstellen | 10 |
12 |
22 |
Figuur 2:
Bestand:TA Tabel1.JPG
De resultaten van tabel 1, die is ontstaan is uit 8M:OM2-Groep6 - Chatlog Analyse 2, stelt ons in staat om een antwoord te destilleren op de tweede onderzoeksvraag.
{kind=link}
We hadden gesteld dat:
1. Een leider doet meer voorstellen dan de andere testpersoon.
2. Een leider doet meer samenvattingen dan de testpersoon.
3. Een leider stelt minder vragen.
4. Een leider doet minder agreements.
In het geval van Harry:
1. Onjuist (10 voorstellen van de 22)
2. Juist (2 samenvattingen van de 3)
3. Onjuist (9 vragen van de 18)
4. Onjuist (10 agreements van de 20)
In het geval van Jan:
1. Juist (12 voorstellen van de 22)
2. Onjuist (1 samenvatting van de 3)
3. Onjuist (9 vragen van de 18)
4. Onjuist (10 agreements van de 20)
Op basis van de analyse kunnen we concluderen dat er geen sprak is geweest van een leider tijdens het gesprek. Het kan zijn dat onze opvatting en de manier waarop wij proberen te achterhalen of er sprake is van een leider onjuist is of het kan wederom met het domein van de opdracht te maken hebben. Wij denken dat het domein weer de boosdoener is aangezien beide testpersonen evenveel kennis hadden. Je krijgt natuurlijk een compleet andere situatie wanneer de ene testpersoon meer weet dan de andere.
Problemen
We zijn helaas ook nog tegen een aantal problemen aangelopen tijdens het uitvoeren van ons onderzoek. We hadden een sessie gepland in het Huygens gebouw, tijdens deze sessie ontstonden er helaas een aantal technische problemen. Ten eerste werkte twee verschillende versies van MSN messenger niet geheel vlekkeloos met elkaar. Hierdoor zag proefpersoon 1 proefpersoon 2 niet en andersom wel. Gevolg dat verschillende berichten niet meer aankwamen en we dus een oplossing moesten vinden. De oplossing was dezelfde versie te gebruiken. Na een lange installatie (waarschijnlijk door Windows Vista) konden we de sessie hervatten. Echter moesten we de sessie na korte tijd weer afbreken aangezien netwerk- en/of systeembeheer de poorten geblokkeerd hadden waardoor er weer geen communicatie onderling mogelijk was. Een derde sessie op een andere dag en locatie verliep gelukkig wel vlekkeloos.
Door deze technische problemen op de geplande locatie hebben we van het idee om via papier het model te communiceren moeten laten varen. We hebben er uiteindelijk voor gekozen om de tekeningen te maken in Microsoft Visio. Om ervoor te zorgen dat de data bruikbaar zou zijn hebben we de proefpersonen in een aparte ruimte geplaatst zodat er geen verbale of andere manier van communicatie kon plaatsvinden behalve die via de chat. De bestanden werden via het chat programa uitgewisseld.
Logboek
| Week | Activiteit |
| Week 38 | - Bepalen onderzoeksmethode/techniek |
| Week 39 | - Bepalen onderzoeksmethode/techniek - Bedenken onderzoeksvraag |
| Week 40 | - Onderzoeksvraag verder uitwerken - Conceptueel model opstellen |
| Week 41 | - Aanpassen onderzoeksvraag - Aanpassen conceptueel model |
| Week 42 | - Bepalen chatprogramma - Bepalen Locatie - Zoeken naar proefpersonen |
| Week 43 | Vakantie |
| Week 44 | - Zoeken naar informatie
mbt tekstanalyse - Benaderen contactpersonen |
| Week 45 | - Zoeken naar informatie
mbt tekstanalyse - Benaderen contactpersonen |
| Week 46 | - Zoeken naar informatie
mbt tekstanalyse - Benaderen contactpersonen |
| Week 47 | - Plannen sessie - Proefpersonen benaderen voor een afspraak |
| Week 48 | - Uitvoeren sessie 1 - Proefpersonen benaderen voor nieuwe afspraak |
| Week 49 | - Zoeken naar ander chatprogramma |
| Week 50 | - Uitvoeren sessie 2 - Chatlog aanpassen en online zetten |
| Week 51 | - Hoofdvraag aanpassen - Analyse op chatlog 1 - Beantwoorden hoofdvraag 1 en conclusie schrijven |
| Week 52 |
- Vakantie - Bedenken van nieuwe vraag, vanwege resultaat op eerste vraag - Analyse op chatlog 1 |
| Week 1 | - Vakantie - Analyse op chatlog 1 - Uitwerken hoofdvraag 2 |
| week 2 |
- Resultaten onderzoeksvraag 2 uitwerken - Presentatie opzet maken |
| Week 3 | - Afronden onderzoek - Complete onderzoek online plaatsen - Presentatie voorbereiden - Presentatie uitvoeren |
| Week 4 | - Complete wiki nalopen op fouten - Tips bij bestpractices voegen - Website op wiki plaatsen |
Tips
Wanneer je voor je onderzoek gebruik wil maken van tekstanalyse bedenk dan goed van te voren waarop je een tekstanalyse gaat toepassen. Dit kan namelijk wel eens cruciaal zijn voor je onderzoek. Wij hebben gekozen voor een chatlog, maar hierdoor kregen we te maken met een aantal problemen. Het eerste probleem is dat je een onderzoeksvraag moet gaan verzinnen op basis van iets dat nog niet heeft plaatsgevonden. Het tweede probleem is dat je van te voren niet weet hoe waardevol je data is. In ons geval laat je twee proefpersonen met elkaar communiceren en daar kun jij als onderzoeker op dat moment geen invloed op uitoefenen. Dit kan er wel eens voor zorgen dat je achteraf je onderzoeks(vraag) moet aanpassen omdat je data anders is dan wat je van te voren had verwacht.
Terugblik
Ondanks dat we geen spectaculair onderzoek hebben gedaan hebben we toch wel kennis gemaakt met het gebruik van tekstanalyse en de mogelijkheden daarvan. Omdat we beide al ervaringen hadden met interviews en workshops was tekstanalyse een leuke uitdaging. Helaas werden we geconfronteerd met een aantal problemen, maar dit is voor ons een goed leerproces geweest.
Directe Links
8M:OM2-Groep6 - Chatlog Analyse 1
8M:OM2-Groep6 - Chatlog Analyse 2
{kind=link}
{kind=link}
{kind=link}
Extra Informatie
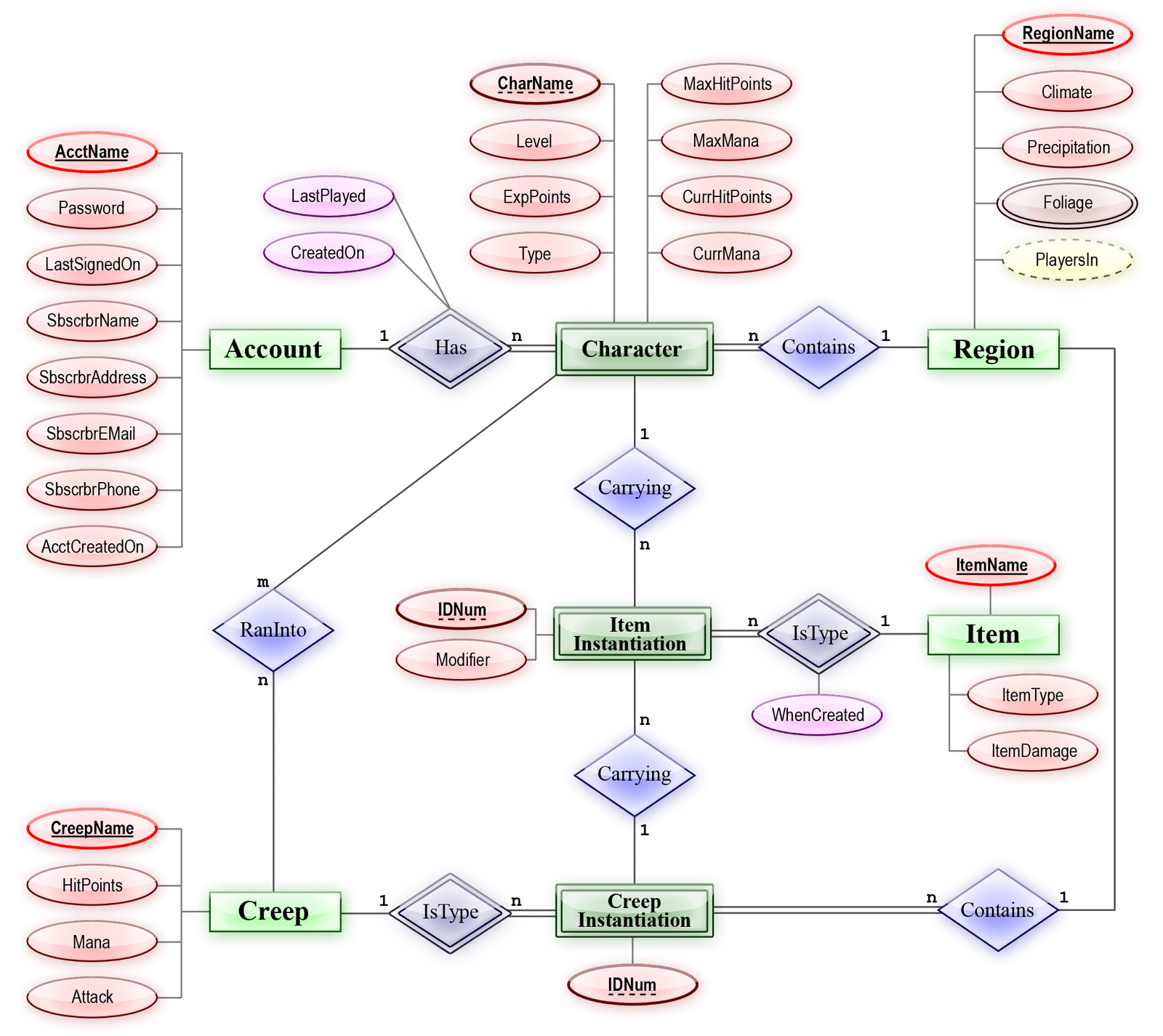
Het entity-relationship-model of entity-relationship diagram (ERD) is een datamodel of diagram voor het grafisch representeren van een conceptueel datamodel. Het is een visuele weergave van de entiteiten, relaties en beperkingen die gelden of aanwezig zijn in een bepaald ontwerp. Deze diagrammen worden gemaakt bij het ontwerpen van een informatiesysteem om inzicht te krijgen in de benodigde informatie en de verbanden tussen de gegevens.
{kind=link}