Onderzoeksmethoden 2/het werk/2008-9/Groep06
Inhoud
Groep 06 - Text Analysis
Inleiding
Bij de cursus Onderzoeksmethoden (vervolg) worden vier verschillende soorten onderzoeksmethoden belicht.
De onderzoeksmethoden die in de colleges aan bod gekomen zijn:
- Interviews
- Tekstanalyse
- Think Aloud Protocols
- Workshops
De klas is verdeeld in groepen, waarbij het de bedoeling is dat elke groep een onderzoek doet aan de hand van één van deze methoden. De resultaten hiervan staan op deze wiki.
Wij hebben gekozen voor Tekstanalyse.
Onderwerp
Bij het kiezen van een onderwerp was het oorspronkelijk de bedoeling te kiezen voor iets wat betrekking had op informatica of informatiekunde. Onze insteek was daarom om een chatgesprek te analyseren en we zijn hierbij voorbij gegaan aan het idee dat de inhoud van de tekst ook betrekking moest hebben of informatica of informatiekunde. Omdat we informatie halen uit de tekst met behulp van software, kun je zeggen dat we toch aan de eerste eis voldaan hebben.
Het centrale onderwerp is actueel, de kredietcrisis. In de NRC Next van dinsdag 7 oktober 2008 hebben we een artikel gevonden waarbij een journaliste, in dit geval Aaf Brandt Corstius, een interview afneemt d.m.v. een chatgesprek, met economisch redacteur Egbert Kalse. De hoofdvragen hebben wij gebruikt om zelf ook nog twee chatgesprekken af te nemen, zodat we deze konden vergelijken.
De chatgesprekken worden gemeten op efficiëntie, waarmee we een onderscheidt maken tussen de chatgesprekken. Hoe hoger de uitslag, des te efficiënter het gesprek.
De methode waarmee dit gedaan wordt is hieronder verder toegelicht.
Probleemstelling
De journaliste in het chatgesprek, Aaf Brandt Corstius, heeft een column geschreven over de kredietcrisis waarin naar voren kwam dat ze eigenlijk niets van de kredietcrisis afweet.
Aan de hand hiervan heeft ze twee vragen:
- Hoe kan de wereld ineens in zo'n crisis raken?
- Moet ik straks uit een vuilnisbak eten?
Om deze vragen te beantwoorden heeft ze een chatgesprek met economisch redacteur Egbert Kalse.
In het chatgesprek staat de volgende vraag centraal, wat tevens de naam van het artikel is:
- Is het een goed idee wat goud in huis te halen?
Bij het beantwoorden van deze vragen is er in het chatgesprek te lezen dat aan de hand van de antwoorden van Egbert Kalse op de vragen van Aaf Brandt Corstius deze weer nieuwe vragen formuleert, afgeleid uit het antwoord van Egbert Kalse.
Om een vergelijking te kunnen maken worden er nog twee interviews afgenomen d.m.v. een chatgesprek. Hierin staan de bovenstaande vragen centraal. De nieuwe vragen die eventueel ontstaan tussen interviewer en ondervraagde kunnen uitgebreider zijn of juist niet. Een methode om de interviews te vergelijken zou kunnen zijn het tellen van het aantal woorden dat wordt gebruikt. Omdat we de efficiëntie willen meten is het efficiënt als de interviewer alleen "ja/nee" vragen zou stellen. Wanneer de woorden worden geteld zou het kunnen zijn dat het gesprek efficiënt verloopt, maar dat er wel veel meer vragen gesteld moeten worden om hetzelfde te weten te kunnen komen. Op de één of ander manier moet het begrip "efficiëntie" meetbaar worden gemaakt, zodat verschillende chatgesprekken kunnen worden vergeleken.
Onze onderzoeksvraag luidt als volgt: Hoe efficiënt worden vragen beantwoord in een interview middels een chatgesprek?
Verantwoording
Om efficiëntie meetbaar te maken gaan we aan elke tag een waarde toewijzen. Dit werkt als volgt.
Een vraag met een direct antwoord dat een antwoord geeft op de gestelde vraag is efficiënt. Je zou kunnen zeggen dat het een efficiëntie heeft van 100%. Een vraag met een direct antwoord. Stel nu dat er wordt getwijfeld in een antwoord, dit is niet relevant voor het antwoord, en dus is dit ruis. Ruis of een doorvraag dat na een antwoord wordt toegevoegd, kan wel van invloed zijn bij het antwoord van een nieuwe vraag. Indirect kan de interviewer hiermee om nieuwe informatie of verduidelijking vragen. De vraag is of dit het gesprek efficiënter maakt of juist niet. Ruis voegt in dit geval niets toe aan het antwoord. Hierom heeft ruis een waarde van 0%. Tussen deze twee uitersten liggen uiteraard meerdere tags die gekwalificeerd moeten worden. Op deze manier kunnen waarden worden toegevoegd aan de tags en dus bij optelling van de waarden krijgt een compleet chatgesprek ook een waarde. Uiteindelijk moet hier een methode uitkomen die de efficiëntie van een chatgesprek laat zien.
Theoretisch kader
Met dit onderzoek willen we meten wat de efficiëntie is van een chatgesprek. Om de efficiëntie te kunnen meten, en een vergelijk te kunnen maken tussen verschillende chatgesprekken, gaan we in verschillende chatgesprekken dezelfde hoofdvragen proberen aan te houden.
Waar ligt nu de grens tussen een efficiënt chatgesprek en een chatgesprek dat minder efficiënt is? Dit willen we meten door de chatgesprekken te taggen, elke tag heeft daarbij een aparte waarde, waardoor er een waarde ontstaat aan de antwoorden van de geïnterviewde. Om een efficiëntie waarde te kunnen bepalen moeten we gaan rekenen met deze waarden. Er wordt rekening gehouden met wat er gemeten wordt, en daaruit moet het efficiëntie getal komen. Door de efficiëntie waarden van chatgesprekken met dezelfde hoofdvragen te vergelijken kunnen we een uitspraak doen over welk chatgesprek het efficiëntst is verlopen.
Methode
Syntax
De teksten hebben we getagd volgens een vaste methode. Het consequent werken met één dezelfde methode is van groot belang, omdat onze opgebouwde tool hierdoor in staat is alle op deze wijze getagde teksten op dezelfde wijze te interpreteren. De formele syntax voor het onze tagmethode is als volgt:
Tag := [ Tagreferentie ; TagList ] TagList := Keyword [, TagList] Tagreferentie := string Keyword := string
Hierbij geldt dat de tag 'Ruis' niet voor kan komen in combinatie met andere tags. De reden hiervoor is dat wanneer ruis voorkomt in een geneste tag, het toegevoegde waarde heeft en dus geen ruis meer is.
Gehanteerde tags
Om de te gebruiken tags te bepalen, hebben we de teksten een eerste keer doorgelezen en gezocht naar type vragen en type beantwoordingen. Deze tags zijn niet op het niveau van betekenis van de inhoud, gekozen zinconstructies of type statements(ontkenning, betoog, afweging, etc.), maar betreffen de manier waarop de beantwoorder heeft gekozen de vraag tracht te beantwoorden. Denk hierbij aan dat een ondervraagde een antwoord direct kan geven, een antwoord kan impliceren met een stelling, een voorbeeld kan geven wat een beantwoording kan illustreren, etc. We hebben voor dit type tags gekozen, omdat hier een duidelijk verschil is tussen de tags in hoe direct, hoe efficient een vraag beantwoord wordt, datgene wat we onderzoeken. Natuurlijk is het mogelijk dat er binnen de categorie 'type beantwoordingen' een wildgroei aan tags ontstaat. We hebben ons daarom ook beperkt tot tags, waarvan we kunnen onderbouwen waarom de door ons hieraan gekoppelde efficientiewaarde te allen tijde gelijk is. Een voorbeeld van een tag, die in de naam al ruimte laat voor verschillende efficientie is 'Opmerking'. Dit is een dergelijk ruim begrip, waardoor je echt de inhoud van de opmerking zou moeten bekijken om te beoordelen wat de toegevoegde waarde van de opmerking is voor de beantwoording, dus wat de efficientiewaarde is. We hebben gekozen voor meer inhoudsvolle tags. Voorbeelden hiervan zijn nuancering, toevoeging en uitspraak. Dit zijn alledrie ook voorbeelden van opmerkingen, maar met een verschillende efficientiewaarde. De gekozen tags zeggen meer over de waarde; een toevoeging bijvoorbeeld 'voegt iets toe', een nuancering bakent een antwoord af.
De betekenis van dergelijke tags geven dus al iets meer prijs over de waarde hiervan, ten opzichte van de beantwoording, maar ook hier blijft het probleem dat dit nog steeds arbitrair is. Daarom hebben we geprobeerd de door ons gekozen efficientiewaarde bij de tags te onderbouwen en vast te leggen, waardoor een dergelijke discussie buiten de scope van ons onderzoek valt. Hier volgt een opsomming van de door ons gebruikte tags, gesorteerd op efficientiewaarde, en voorzien van een uitleg en onderbouwing over hoe deze in dit onderzoek gehanteerd zijn.
Bij het vastleggen van datgene wat wij als vraag taggen, beperken wij ons tot wat de interviewer zegt. Zo ook, de tags van de beantwoording worden niet gebruikt in de tekst van de interviewer.
Omdat we ons focussen op de beantwoording van de vraagstellingen is een efficientiewaarde voor de vraagstelling niet relevant voor het onderzoek. Daarom hebben we dit achterwege gelaten. Wij hanteren de volgende tags voor de vraagstellingen:
- vraag
- doorvraag
Voor de beantwoordingen is het belangrijk het door ons gehanteerde verschil tussen antwoord en beantwoording te kennen. Een antwoord is namelijk een tag, terug te vinden in onze volgende tabel, met een beantwoording bedoelen we de reactie van een ondervraagde op een vraagstelling.
De volgende tags hanteren we voor de beantwoording, gesorteerd op efficiëntiewaarde:
| Efficiëntie waarde | Tagnaam | Definitie | Onderbouwing |
|---|---|---|---|
| 1,0 | Antwoord | Een directe beantwoording van de vraagstelling. | Wanneer de gegeven beantwoording door de ondervraagde een direct inhoudelijk passend antwoord vormt op de vraagstelling(onafhankelijk van de correctheid van het antwoord), is dit maximaal efficient beantwoord. |
| 0,9 | Voorbeeld | Een voorbeeld wat direct betrekking heeft op de beantwoording. | Het gebruiken van een voorbeeld om een beantwoording te illustreren of kracht bij te zetten, werkt zeer verhelderend. Van de lezer wordt slechts verwacht het voorbeeld in verband te zien tot het antwoord. Hierdoor stellen wij de waarde van een voorbeeld hoog, maar niet gelijk aan een direct antwoord. |
| 0,9 | Nuancering | Een extra afbakening van het de beantwoording. | Het nuanceren van een beantwoording heeft direct invloed op de betekenis van het antwoord. De lezer heeft al begrip voor het antwoord, maar de nuancering zal dit begrip nog meer verfijnen. De nuancering is daardoor van hoge toegevoegde waarde. |
| 0,8 | |||
| 0,7 | Verklaring | Een verklaring voor een gegeven antwoord op een vraag. | Een verklaring voor een gegeven antwoord is niet direct van invloed op de inhoud van de beantwoording. Wanneer de beantwoorder doorgaans een verklaring gebruikt, zal hij dit doen om meer begrip te creëeren voor de beantwoording. Dit beoordelen we wel als toegevoegde waarde in het beantwoorden van een vraagstelling, en is daarom van behoorlijke efficiëntiewaarde. |
| 0,6 | Implicatie | Een indirecte beantwoording wat een direct antwoord impliceert. | Dit is een omslachtige wijze van het beantwoorden van de vraag. Wanneer de lezer in staat is de slag te maken om de implicatie als dusdanig te herkennen, zal hij echter wel in staat zijn het directe antwoord wat de ondervraagde bedoelt hieruit te onttrekken. |
| 0,5 | |||
| 0,4 | Toevoeging | Een extra toevoeging op de beantwoording met betrekking op de vraagstelling. | We beoordelen een beantwoording als toevoeging wanneer de inhoud van deze beantwooring niet direct een deel van het antwoord vormt op de vraagstelling, maar wel een dusdanig informatief waardevolle toevoeging is op de vraagstelling, zodat dit op zekere wijze bijdraagt aan het begrip van het overige deel van de beantwoording. |
| 0,3 | |||
| 0,2 | Uitspraak | Een informatieve opmerking wat weinig tot geen betrekking heeft op de vraagstelling. | We beoordelen een beantwoording als uitspraak wanneer de inhoud van deze beantwoording wel een informatief waardevolle toevoeging is op een eerder of later gegeven beantwoording, maar niet iets nieuws aan de beantwoording toevoegt dat direct in relatie staat tot de vraagstelling. |
| 0,1 | Herhaling | Een herhaling van de beantwoording. | De beantwoording is in gelijke of enigzinds afwijkende vorm reeds gegeven. Het herhalen hiervan is niet efficient. In enkele gevallen kan het wel de relevantie van de eerder gegeven beantwoording benadruken. |
| 0,0 | Ruis | Niet relevantie opmerkingen. | Alles wat op geen enkele wijze betrekking heeft op of iets toevoegd aan een vraagstelling of beantwoording, bevat geen enkele efficiëntiewaarde. |
Variabelen
Nu we de efficiëntiewaarde van de tags hebben vastgelegd, kunnen we opstellen hoe we deze waarden gaan gebruiken om tot een uiteindelijke waarde te komen voor de efficiëntiewaarde per beantwoording op een vraagstelling en uiteindelijk tot een waarde voor het gehele interview. Voordat we deze hiervoor ontwikkelde formules hanteren, eerst een overzicht van de hierin voorkomende variabelen en de hierbij behorende betekenissen:

Over een aantal variabelen zal nog onduidelijkheid zijn waarom deze bestaan. Dit is terug te vinden in de uitleg bij de formules.
Formules
Voordat we overgaan tot het toelichten van de formules, die leiden tot efficientiewaarden die antwoord geven op onze onderzoeksvraag, willen we nog een nuance aanbrengen in de te gebruiken efficientiewaarden zoals zojuist in de tabel is opgesomd. Dit betreft de situatie wanneer in een beantwoording de ondervraagde door middel van een type beantwoording zoals in de bovenstaande tabel genoemd is, doorgaat op een eerder gegeven beantwoording, dat geen direct antwoord was. In de meeste gevallen is dit niet het geval en is een tag of een directe beantwoording(antwoord, implicatie), of heeft het betrekking op een al gegeven direct antwoord(bijvoorbeeld een voorbeeld dat volgt op een direct antwoord).
Een voorbeeld van wanneer deze situatie zich wél voordoet is wanneer de ondervraagde een toevoeging doet, wat efficientiewaarde 0.4 heeft, en vervolgens een verklaring voor deze toevoeging geeft, wat efficientiewaarde 0.7 heeft. Wanneer we deze verklaring als slechts een verklaring zouden taggen, ontstaat de vreemde situatie dat een verklaring voor iets wat niet eens erg relevant is voor de beantwoording een zeer hoge efficientiewaarde heeft. We vangen dit op door in dit geval twee tagnamen aan de tags te koppelen. Als dit het geval is wordt er als volgt getagged: [tekst; toevoeging, verklaring]. de waarde hiervoor berekenen we door deze met elkaar te vermenigvuldigen.
In de formulevorm ziet dit er als volgt uit:
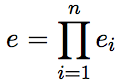
Wanneer er dus meerdere tagnamen bij een tag staan, wordt dus niet meer de efficientiewaarde overgenomen van de tagnamen, maar wordt deze berekend door middel van bovenstaande formule. Hierin is de efficientiewaarde het cartesisch product van alle efficientiewaarden behorende bij de tagnamen van de tags 1 tot en met n, behorende bij de betreffende tag.
Uit de eerder gegeven lijst met variabelen is al te zien dat er nog iets gaat gebeuren met de efficientiewaarde van de ruis-tags. De reden hiervoor is de volgende. Aangezien ruis van zeer uitéénlopende grootte kan zijn, is het niet correct een ruistag te allen tijde even zwaar mee te laten wegen in de berekening van de efficientie. Wanneer iemand bijvoorbeeld slechts eenmaal 'eeuh' zegt, is dit weleenswaar niet efficient(efficientiewaarde = 0.0), maar de invloed op de totale efficientie van de beantwoording is natuurlijk minimaal. Wanneer iemand ineens een voor de vraagstelling totaal irrelevant verhaal afsteekt van meer dan 100 woorden, is dit ook niet efficient, maar daarnaast van grote invloed op de totale efficientie van de beantwoording. Verhoudingsgewijs is de hoeveelheid ruis velen malen groter. Een lagere efficientiewaarde voor de totale beantwoording is dan veel realistischer.
Om dit probleem op te vangen, hebben we een constructie bedacht, waarbij we de grootte van de tag een gewogen invloed willen laten hebben op de efficientie van de beantwoording.
We zullen eerst de gemiddelde lengte in woorden van een tag uitrekenen over het gehele interview. Hierbij laten we alles wat als ruis getagd is achterwege, omdat dit juist deze waarde kan misleiden wanneer er extreem grote of kleine ruistags overheersend zijn. In de formule is dit g, het gemiddeld aantal woorden per tag. Dit berekenen we door het aantal woorden in alle tags te delen door t, het aantal tags. We berekenen g éénmalig, over het gehele interview. Deze waarde zal gehanteerd worden voor iedere berekening van Eb, de Efficientie van de beantwoording. Wanneer deze waarde bekend is, kan de hoeveelheid ruis per beantwoording gewogen bepaald worden. Dit doen we door het aantal ruiswoorden dat in totaal in een beantwoording voorkomt, te delen door g, het gemiddelde aantal woorden per tag. Hier komt een waarde uit die de hoeveelheid ruis in een beantwooding uitdrukt in een hoeveelheid tags, gewogen dus door g. Door deze waarde op te tellen bij het overige aantal tags in de beantwoording, ontstaat er een nieuwe waarde.
In formulevorm ziet de efficientie voor een beantwoording er dan als volgt uit:
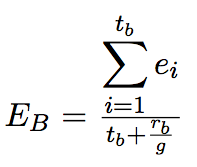
We bereken de efficientie van de beantwoording door het gemiddelde te nemen van de efficientiewaarden, die passen bij alle tags die gebruikt zijn in de beantwoording. Dit berekenen we door de som van alle efficientiewaarden uit de beantwoording te delen door de som van het aantal tags en het gewogen aantal ruistags.
Om vervolgens tot een totale efficientewaarde te komen berekenen we het gemiddelde van alle efficientiewaarden van beantwoordingen in het interview. Dit ziet er in formulevorm als volgt uit:
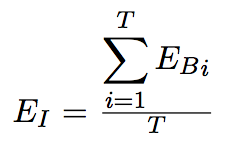
De som van alle efficientiewaarden van beantwoordingen, gedeeld door het totaal aantal vragen in het interview, levert de efficientiewaarde op van het totale interview.
Planning
Bijeenkomsten van onze projectgroep staan gepland op:
- Dinsdag van 13.45 uur tot 15.30 uur
- Donderdag van 10.45 uur tot 12.30 uur
Data structurering
Chatgesprek 1
| Chatgesprek1 incl. tags |
|---|
|
E zegt: Ha Aaf A zegt: Hoi Egbert, daar ben ik, met vraag 1: [Wat is, in één zin, de kredietcrisis?; vraag] E zegt: [Een crisis in de financiële wereld waardoor niemand elkaar meer vertrouwt; antwoord], [dat is eigenlijk de simpelste uitleg; ruis]. A zegt: En [waarom vertrouwt niemand elkaar meer?; vraag] E zegt: [Omdat niemand meer van elkaar weet hoeveel risico de ander loopt; antwoord]. [Simpel voorbeeldje; ruis]: [als jij je geld uitleent aan een vriendin van wie je niet weet of ze al diep in de schulden zit, dan aarzel jij neem ik aan ook om dat geld uit te lenen; voorbeeld]. [Dat werkt bij banken net zo; toevoeging]. A zegt: [Dus niemand durft meer geld uit te lenen?; vraag] E zegt: [Nee; antwoord], [en; ruis] [dat komt omdat al die banken hebben belegd in waanzinnig ingewikkelde producten. Die zijn zo ingewikkeld, dat de banken vaak zelf niet meer weten welk risico ze daarmee lopen; verklaring]. [Weer een simpel voorbeeldje:; ruis] [banken hebben allemaal (en dan bedoel ik ook echt allemaal) belegd in obligaties waar Amerikaanse hypotheken als onderpand dienen. Nu in Amerika de huizenprijzen de kelderen en mensen uit hun huizen worden gezet en hun hypotheken niet meer kunnen betalen, raakt dat dus alle banken; voorbeeld]. A zegt: Dus nog even samengevat, door mij, als nitwit. De banken hebben huizen als onderpand gebruikt. Maar de huizenprijzen kelderen. Dus de huizen zijn niks meer waard. En [daardoor kunnen de banken hun leningen niet terug betalen?; vraag] Sorry hoor, maar het is best mysterieus allemaal. E zegt: [Dat is het ook, maar; ruis] [je samenvatting klopt!; antwoord] [Jij vraagt je natuurlijk af waarom jouw bank in Nederland in hemelsnaam in Amerikaanse hypotheken gaat beleggen? Dat komt omdat ze dachten daar meer geld mee te kunnen verdienen dan met andere beleggingen.; toevoeging] [Iedereen (dan bedoel ik voor de verandering maar weer eens echt iedereen) dacht dat de huizenprijzen in Amerika altijd zouden blijven stijgen. Dom natuurlijk, maar zo was het wel. En omdat iedereen dat dacht, dacht ook iedereen dat het wel veilig was daarin te beleggen. Niet dus.; toevoeging, verklaring] A zegt: O! Oké, dat is duidelijk. Dan nu een andere vraag. [Hoe kan de wereld van de ene dag op de andere - zo voelt het tenminste - in een crisis raken?; vraag] E zegt: [Ja, dat is fascinerend.; uitspraak] [Het heeft alles te maken met angst.; implicatie] [Maar eerst even dit:; ruis] [de kredietcrisis is alweer 14, 15 maanden bezig, maar tot nu toe leek het een probleem dat zich vooral bij Amerikaanse zakenbanken afspeelde en een paar Europese banken die heel veel hadden belegd in Amerikaanse hypotheken.;toevoeging] [Maar ja,;ruis] [beleggers zijn ook mensen en als de crisis maar lang genoeg aanhoudt, raakt op een gegeven moment iedereen in paniek.;antwoord] [Mensen gaan dan echt letterlijk wegrennen van hun beleggingen.; toevoeging] [Je zag het twee weken geleden op maandag: niemand had nergens meer vertrouwen in, de aandelenbeurzen kelderden en, erger nog, mensen begonnen hun geld weg te halen bij hun banken.;voorbeeld] [En dan is het pas echt crisis.; uitspraak] A zegt: Ik voel de paniek inmiddels zelf ook een beetje. Daarom een paar vragen: [gaat de crisis mij (33, huisbezitter, beetje spaargeld) hard raken?; vraag] E zegt: [Dat denk ik eerlijk gezegd niet, althans, niet op hele korte termijn.; antwoord] [Jij hebt een huis en dus een hypotheek. Als je de afspraak hebt dat die bijvoorbeeld de komende 5 jaar een vaste rente heeft, blijf jij dus gewoon elke maand datzelfde bedrag aan je bank betalen. Er even vanuit gaande dat je een inkomen blijft houden, moet dat dus geen probleem opleveren. Wat je nooit kunt weten is, hoe hoog de rente zal zijn als je huidige periode afloopt en je een nieuwe afspraak moet maken met je bank. Die onzekerheid heb je altijd, crisis of niet.; voorbeeld] [Je spaargeld staat veilig, sterker nog, dat wordt nog beter.; antwoord] [De Staat garandeert je ongeveer 38.000 euro als je bank failliet zou gaan en while we Skype is minister Bos in Brussel bezig om dat bedrag nog op te hogen.; verklaring] [Zolang je minder dan 40.000 euro op de bank hebt, is er dus geen enkel probleem.; nuancering] A zegt: En [zou het kunnen dat we over een tijdje niet meer kunnen pinnen - dat scenario las ik ergens - en uit prullenbakken eten?; vraag] E zegt: [Ook; ruis] [dat valt wel mee.; antwoord] [Nederland kent 4 grote banken, ABN, Fortis, ING en Rabobank, en die zijn allemaal zo belangrijk voor het functioneren van de Nederlandse maatschappij dat de Staat die nooit zal laten omvallen (kijk maar wat er dit weekende met Fortis en ABN gebeurde, gewoon gered door minister Bos).; verklaring] [Aan jouw leven verandert weinig.; implicatie] [Kijk, als de crisis lang aanhoudt kan het natuurlijk wel zo zijn dat ook de reële economie (die waar jij en ik iedere dag in rond lopen) er wat van gaat merken.;nuancering] [Bedrijven hebben geen geld meer om bijvoorbeeld uit te breiden (kan ook de kaaszaak bij jou op de hoek zijn). Of de werkeloosheid loopt op, waardoor het moeilijker wordt om aan een baan te komen.;nuancering, verklaring] [Maar het is nu nog heel moeilijk in te schatten of, en zo ja hoe erg dat als gevolg van deze crisis zal toeslaan.; nuancering, nuancering] A zegt: [Wie moeten er wel gaan oppassen?; doorvraag] [Mensen met veel geld?; doorvraag] E zegt: [Ja; antwoord] [,die hebben een wat groter probleem; uitspraak] [,zou je kunnen zeggen.; ruis] [Ten minste als ze meer dan 40.000 euro op de bank hebben staan, dan wordt dat meerdere niet vergoed als het fout gaat.; verklaring] [En; ruis] [beleggers moeten helemaal oppassen; antwoord] [natuurlijk.; ruis] [Daar geldt een hele andere grens.; toevoeging] [Logisch ook,; ruis] [je zou het in tijden van economische voorspoed bijna vergeten, maar beleggen is een vorm van risico nemen.; verklaring] [De mensen die in Fortis hebben belegd, zijn weer even met de neus op de feiten gedrukt. Hun aandelen zijn nog maar iets van 4 euro per stuk waard, een jaar geleden nog ruim 30 euro per stuk.; voorbeeld] [Jammer maar helaas, hadden ze het maar op hun spaarbank moeten zetten.; uitspraak] A zegt: [Dus beleggen is dom?; doorvraag] E zegt: [Beleggen is risico nemen.; implicatie] [En; ruis] [wie risico neemt, kan zijn geld kwijtraken.; verklaring] A zegt: Wat ik niet snap: een bank is een commerciële instelling. En [nu het even slecht gaat met Fortis, neemt de Nederlanse Staat het gewoon over. Zo makkelijk. Dat kan toch niet zomaar?; vraag] [Dat is toch niet eerlijk tegenover andere banken en bedrijven die het moeilijk hebben?; vraag] E zegt: [Wees blij, zou ik in dit geval zeggen.; ruis] [Als de staat niet had geholpen, was Fortis echt omgevallen (failliet gegaan).; implicatie] [En;ruis] [dan waren niet alleen een heleboel mensen geduppeerd (zij die meer dan 40.000 op de bank hadden staan bijvoorbeeld), maar waren er ook een hoop werkelozen bij gekomen en liepen al die andere banken, die van en aan Fortis geld hadden uitgeleend, grote risico's.;implicatie] [Dat is wat Nout Wellink van De Nederlandse Bank een 'systeemrelevante bank' noemt: cruciaal voor het functioneren van de Nederlandse geldmarkt.; toevoeging] [Maar je hebt wel een punt hoor,;ruis] [waarom redden ze die bank wel als het mis gaat en bijvoorbeeld die kaasboer bij jou op de hoek niet.; herhaling] [Het ergste van alles is dat banken daar ook op rekenen, dat ze worden gered als het mis gaat.; toevoeging] [Nog een keer die kaasboer: die zorgt ervoor dat hij een potje achter de hand heeft voor als het even tegenzit.;voorbeeld] [Keurig, met gezond verstand ondernemen, wat mij betreft.;voorbeeld, uitspraak] [Maar;ruis] [die banken, die hebben amper geld achter de hand als het mis gaat. Die redeneren als volgt: als we vallen, komt de overheid ons wel helpen. Dus tot die tijd hoeven we nergens rekening mee te houden en kunnen we lekker geld verdienen!; toevoeging, verklaring] A zegt: Wat een boeven eigenlijk. [Wat wordt er trouwens precies bedoeld met banken die 'omvallen'?; vraag] [Is het echt als een soort domino?; vraag] Dat de ene bank de andere bank meesleept in zijn val? E zegt: [Een beetje wel; antwoord] [, zoals ik net al zei,;ruis] [al die banken lenen geld van en aan elkaar. Als er eentje gaat, loopt de rest het risico ook te gaan. Daarom vertrouwen ze elkaar ook niet meer en is de markt van onderling aan elkaar lenen opgedroogd, zoals dat heet.; verklaring] [En; ruis] [omvallen is een alternatief voor falliet gaan.;antwoord] [Al gebruiken wij omvallen ook weleens als een soort voorportaal van een faillissement.; nuancering] [De Amerikaanse zakenbank Bear Stearns viel in maart dit jaar om, maar werd opgekocht. De Amerikaanse zakenbank Lehman Brothers viel om en ging ook echt failliet (in september was dat).; nuancering, voorbeeld] A zegt: Wat ik ook zo'n wonderlijk geval vind, is virtueel geld. Geld dat er eigenlijk niet is. Banken hèbben helemaal niet al dat geld dat de rekeninghouders daar hebben neergezet, lees ik. Het is 'virtueel geld'. En daarom moeten we vooral niet met z'n allen naar de bank lopen om ons geld op te nemen, want dat ìs er dan niet. Maar [dat geld dat de overheid nu in de banken steekt, is dàt dan wel echt geld?; vraag] E zegt: [Al het geld is echt, zolang wij daarin geloven.; antwoord] [Heeeeeeel vroeger was er voor elke gulden (je weet wel) bepaalde hoeveelheid goud, zodat je altijd je gulden in kon ruilen voor dat goud.; voorbeeld] [Daar zijn we allang vanaf gestapt, en;ruis] [nu is het zo dat de staat degene is die bepaald wat de waarde van het geld is.;toevoeging] [Normaal gesproken gaat dat redelijk goed.;uitspraak] [Elk jaar komt er een beetje geld bij, soms wat meer dan de producten die we maken (dat heet dat inflatie).;toevoeging, uitspraak] [Maar soms gaat het ook helemaal mis;uitspraak, nuancering] [(zoek maar eens op Google naar Zimbabwe en inflatie).; voorbeeld] A zegt: Nog even over het geld. Ik las dat er een econoom is die liever goud dan geld in huis heeft. Omdat goud niet in waarde kan verminderen. [Is het een goed idee om wat staafjes goud in huis te halen?; vraag] E zegt: [Goud wordt nog steeds gezien als een zeer waardevaste vorm van beleggen.; uitspraak] [Maar zoals het woord al zegt, het blijft een belegging.; herhaling] [Omdat goud van oorsprong de functie had van maatstaf voor al het geld, vluchten beleggers nog steeds in goud als het fout gaat met de rest van de aandelen.; toevoeging] [Maar ook de goudprijs kan enorm schommelen; nuancering] [, dus; ruis] [je moet niet raar opkijken als je nu zeg 1.000 euro omzet in goudstaven (ik geloof dat je dan iets van 35 gram kunt kopen nu) en dat over een half jaar datzelfde goud nog maar 700 euro waard is.; voorbeeld] [Ook; ruis] [hier geldt: geen garanties!; implicatie] A zegt: [Dus niks is veilig. Ook niet je geld in een oude sok onder je bed bewaren.; vraag] E zegt: [Als je een goede inbraakbeveiliging hebt, is dat veilig.; antwoord] [Alleen wordt dat geld elk jaar relatief minder waard (vanwege de inflatie).; toevoeging] A zegt: Ja, dat bedoelde ik. Dat al dat geld misschien straks niks meer waard is. Nog een vraag. Banken hebben geld tekort. Begrijp ik. De overheid steekt er nu veel geld in. Begrijp ik ook. Maar [de overheid leent dat geld weer bij banken. HOE KAN DAT?; vraag] Van dit soort zaken wordt een niet-econoom helemaal wanhopig... E zegt: [Ha ha,; ruis] [ja, dat lijkt vreemd inderdaad.; uitspraak] [Maar ik kan het (hoop ik) uitleggen.; ruis] [De Nederlandse overheid heeft nu bijvoorbeeld 16,8 miljard euro betaald voor Fortis. Als ze dat geld zelf zouden bijdrukken, vliegt de inflatie omhoog (het is ruim 3 procent van wat we in Nederland in een jaar verdienen!).; toevoeging] [Wat ze dus doen is het geld lenen, zodat de staatsschuld omhoog gaat. Dat geld lenen ze vaak bij andere overheden, maar ook bij banken, verzekeraars, pensioenfondsen, of multinationals.; antwoord] [En; ruis] [de overheid is dankzij de kreditietcrisis enorm populair geworden om geld aan uit te lenen. Immers: de overheid kan niet failliet.; uitspraak] [Een bank die geld op zijn balans leent (is oude sok) en er toch nog iets op wil verdienen, leent het dus liever uit aan de overheid voor een rente van zeg 3 procent, dan dat-ie het aan een andere bank uitleent voor zeg 5 procent.; verklaring] A zegt: Mijn hersens kraken op dit moment. E zegt: [Ze kopen er ook een hele bank voor, de overheid is nu de eigenaar van Fortis. En als ze dat later weer verkopen, hebben ze weer geld om die leningen af te lossen.; toevoeging] A zegt: [Maar hoe weet de overheid dat ze winst gaan maken op Fortis?; vraag] E zegt: [Dat weet de overheid niet zeker; uitspraak] [, het is een belegging; uitspraak, verklaring] [en zoals ik al zei:; ruis] [Beleggen brengt risico's met zich mee.; uitspraak] [Echter, de kans dat ze er winst op maken is best groot.; uitspraak, nuancering] [De Nederlandse overheid heeft namelijk keihard met de Belgen onderhandeld over de prijs. Belgie wilde veel meer geld hebben voor ABN Amro, Fortis Nederland en Fortis Nederland verzekeringen. Maar dat lieten Bos, Balkenende en Wellink niet gebeuren. Zij zagen ook dat de Belgen redelijk wanhopig op zoek waren naar geld om de rest van Fortis overeind te houden. Dat gaf Nederland een goede positie om te onderhandelen.; uitspraak, nuancering, verklaring] [Als de crisis voorbij is (niet vragen hoelang dat nog duurt, dat weet ik echt niet en niemand weet dat), kan Nederland eens rustig kijken aan wie ze de bank willen verpatsen. Voor een mooie prijs het liefst.; uitspraak, nuancering, toevoeging] A zegt: Sluw! Die Nederlandse overheid toch. [Dat geeft meteen antwoord op mijn vraag over de Boze Belgen.; vraag] E zegt: [Die waren ook nog boos omdat Bos had gezegd dat de Belgen met het slechte deel van Fortis bleven zitten. Dat klopt wel, maar is niet zo netjes om te zeggen.; toevoeging] A zegt: [Er worden door de overheid reusachtige bedragen gestopt in banken zoals Fortis. Wat wordt er eigenlijk met dat geld gedaan?; vraag] E zegt: [Dat geld hebben ze nodig om aan hun verplichtingen te kunnen voldoen.; antwoord] [Een bank heeft een bepaald eigen vermogen (onder andere van jouw spaargeld) en daarmee gaan ze beleggen. Als die beleggingen ineens verlies maken, hebben ze meer eigen vermogen nodig om die verliezen mee te kunnen betalen. Maar dat geld hebben ze nu niet. Om te voorkomen dat die banken hun deuren moeten sluiten en al die beleggingen in rook opgaan, stoppen overheden geld in banken zodat ze hun verplichtingen weer na kunnen komen.; verklaring] A zegt: [Kan de crisis ons, gewone mensen met gewone huizen en gewone inkomens, wél raken op korte termijn?; vraag] E zegt: [Eigenlijk niet; antwoord] [, volgens mij.; nuancering] [Sommige mensen zeggen dat de huizenprijzen binnenkort ook in Nederland gaan dalen. Dat kan vervelend zijn voor mensen die hadden gerekend op een hoge opbrengst, of voor mensen die hun huis als een soort van pensioen zagen. Er kan een punt komen dat je huis minder waard wordt dan de hypotheek die je hebt afgesloten. Dat zal de bank niet leuk vinden, want die loopt dan een groter risico als jij je hypotheek niet meer kunt betalen; verklaring] [(het onderpand is minder waard dan de schuld,; herhaling] [dat is er in Amerika nu aan de hand).; uitspraak] [En wat ik eerder zei:; ruis] [omdat banken zo bang zijn om geld uit te lenen aan elkaar of aan andere bedrijven, kunnen die bedrijven ook minder investeren. Dat gaan we ook merken, de groei in Nederland zal afremmen, de werkloosheid gaat oplopen.; toevoeging] [Maar of we in een recessie terecht komen, ik durf het niet te zeggen. En wat jij en ik ervan gaan merken, ook geen idee.; antwoord] [Dat is het rare van deze crisis:; ruis] [het blijft een soort ver-van-mijn-bedcrisis. Maar zeg eens eerlijk, dat was de internetcrisis toch ook?; uitspraak] A zegt: Oké Egbert. Laatste vraag. Ik vind je redelijk ontspannen in de hele crisis staan. [Maken we ons dan allemaal om niks zorgen?; vraag] E zegt: [Heel eerlijk gezegd maak ik me persoonlijk weinig zorgen; antwoord] [, maar kijk om je heen en je ziet wel een heleboel 'schokkende' dingen gebeuren.; nuancering] [Al die banken die in de problemen raken, betekent natuurlijk wel iets. Al was het maar omdat ze geen geld meer kunnen uitlenen en dat de groei afremt. En al die pensioenfondsen die hun geld hebben belegd en nu dat kapitaal in waarde zien dalen.; toevoeging] [Maar één ding weten we allemaal zeker: over een tijdje gaat de beurs weer omhoog, en dan is iedereen deze crisis weer vergeten.; uitspraak] [Tot de volgende crisis natuurlijk.; ruis] |
Chatgesprek 2
| Chatgesprek2 incl. tags |
|---|
|
W zegt: Hoi Corjanne, [ben je klaar voor het interview?;vraag] C zegt: [Ja;antwoord] [, helemaal.;herhaling] W zegt: Ok, dan kom ik met mijn eerste vraag. [Kan je me kort uitleggen wat de kredietcrisis precies is?;vraag] C zegt: [Volgens mij is de kredietcrisis begonnen in Amerika.;uitspraak] [Daar is het consumentenvertrouwen in de financiële wereld en het vertrouwen van banken en financiële instellingen in elkaar langzaam weggeëbd;implicatie]. W zegt: [En als het vertrouwen in elkaar wegebt, hoe is dat dan een oorzaak van de crisis?;vraag] [Wat gebeurt er dan precies?;vraag] C zegt: [Dan gaan de consumenten minder besteden en zijn ze bang om grote aankopen te doen,;antwoord] [zoals een huis.;voorbeeld] [Doordat de banken elkaar niet meer vertrouwen, willen ze geen geld meer aan elkaar lenen en wordt het financiële systeem star en strak, wat ertoe leidt, dat als er een kleine schommeling is, er meteen problemen zijn. En problemen leiden tot een crisis.;antwoord] W zegt: Ik ben een leek hoor, maar [een kleine schommeling waarin precies, bedoel je?;doorvraag] C zegt: [Een kleine schommeling in aandelen.;antwoord] [Een bank krijgt het opeens zwaar, doordat de beleggingen iets minder gaan. In een gezonde financiële wereld zou ze dan zonder problemen geld kunnen lenen om deze tijdelijke situatie even op te lossen, maar in tijden van crisis wordt er niet meer geleend.;verklaring] [Begrijp je het nu?;ruis] [Een bank kan dan zomaar failliet gaan, terwijl er niet zoveel aan de hand is.;verklaring, toevoeging] W zegt: [Dus als ik het goed begrijp begint een crisis bij de banken. Pas als de consumenten hier lucht van krijgen en angst krijgen ontstaan de echte problemen?;vraag] Klopt dit? C zegt: [Tegelijkertijd is het een samenspel tussen de banken en de consumenten.;implicatie] [Doordat de consumenten angstig worden gaan ze minder kopen, de beleggingen gaan naar beneden, crisis bij de banken, de banken lenen niets meer uit.;implicatie, verklaring] [Ook bijvoorbeeld hypotheekverstrekkingen worden moeilijker, waardoor consumenten nog minder gaan besteden.;implicatie, verklaring, voorbeeld] W zegt: Ok, dat begint duidelijk te worden. Maar nu eigenlijk de centrale vraag: [Moet ik me, als student met een beetje spaargeld, zorgen gaan maken?;vraag] C zegt: [Nee;antwoord] [helemaal niet,;herhaling] [je spaargeld staat veilig in Nederland.;verklaring] [En verder moet je je er weinig van aantrekken, lekker verder leven.;uitspraak] W zegt: [Ik hoef me ook geen zorgen te maken dat ik op een dag niet meer kan pinnen, en uit de prullenbak moet gaan eten?;vraag] C zegt: [Nee;antwoord] [helemaal niet.;herhaling] [De regering heeft goede plannen voor een dergelijke crisis en zal dat waar jij bang voor bent nooit laten gebeuren.;verklaring] W zegt: Ja, de regering lijkt als het nodig is in te springen. [Maar is het wel eerlijk voor andere banken dat de regering bijvoorbeeld Fortis ineens lijkt te helpen?;vraag] C zegt: [Dat kan je je afvragen.;implicatie] [Ik vind het op zich niet verkeerd dat ze helpen.;uitspraak] [Als ze dat niet zouden doen, zouden wij hier een flinke crisis krijgen. Maar ik vind het niet eerlijk dat Fortis nu reclame gaat maken dat als je daar je geld wegzet, het erg veilig staat, omdat ze nu deel van de staat zijn. Dat terwijl de banken/verzekeraars die het op eigen kracht doen eigenlijk veel gezonder zijn, financieel gezien.;implicatie, verklaring] W zegt: [Maar die hebben er waarschijnlijk ook weer baat bij, dat de regering het land uit de crisis probeert te halen?;doorvraag] C zegt: [Ja;antwoord] [dat is waar,;herhaling] [maar het moet niet tot oneerlijke concurrentie gaan leiden en dat gebeurt nu soms wel.;nuancering] W zegt: Ik snap wat je bedoeld. Iets wat ik ook lastig vind is om in deze tijd de waarde van geld in te schatten. [Ik hoorde een econoom zeggen dat het misschien slim is wat staafjes goud aan te schaffen. Zit hier iets in?;vraag] [Of moet ik geld gewoon in een sok gaan bewaren?;vraag] C zegt: [Goud is iets wat over het algemeen zijn waarde behoudt.;implicatie] [Geld in een sok is echter zeer onverstandig.;antwoord] W zegt: Ok, dan ga ik dat maar overwegen. [Kan ik uit dit interview concluderen dat de man van de straat eigenlijk zich zorgen maakt om niets?;vraag] C zegt: [Juist.;antwoord] [Gewoon lekker blijven consumeren!;uitspraak] [Wanneer je gewoon je normale leefpatroon aan blijft houden, help je jezelf en je landgenoten het meest.;toevoeging] W zegt: [Ok, angst is dus ook in deze een slechte raadgever....;vraag] C zegt: [Ja;antwoord] [dat klopt,;herhaling] [dat zie je goed.;herhaling] W zegt: Dankjewel voor deze korte bijspijkercursus! C zegt: Graag gedaan! |
Chatgesprek 3
| Chatgesprek3 incl. tags |
|---|
|
R zegt: Hoi Dick D zegt: Hoi Roland R zegt: Nou mijn eerste vraag: [wat is de kredietcrisis?;vraag] D zegt: [Kredietcrisis is eigenlijk een tekort aan liq.middelen op de kapitaalmarkt.;antwoord] [Tekort wat is ontstaan door het feit dat aandelen kelderden door Amerikaanse toestanden en daardoor banken elkaar niet meer vertrouwden m.b.t het uitlenen van geld.;toevoeging] [Amerikaanse banken waren niet meer te vertrouwen omdat ze bewust (?) risico's aan andere banken hadden overgedragen.;verklaring] R zegt: [En hoe onstaat dat vertrouwensverlies van banken onderling?;doorvraag] D zegt: [Doordat risico's door drie grote banken zijn overgedragen aan meerdere kleinere en hun weer risico's wederom hebben overgedragen aan kleinere banken, verzekeringsmaatschappijen en particuliere/zakelijke beleggers is het vertrouwen geschaad.;antwoord] [We hebben het hier natuurlijk over miljarden US dollars.;toevoeging] [Banken en beleggers hadden aandelen in hun bezit die uiteindelijk niets waard bleken te zijn.;verklaring] [De waarde van onderpanden (zoals huizen) verdween als sneeuw voor de zon.;voorbeeld] R zegt: Oké het is me grotendeels duidelijk, maar [zoiets gebeurt toch niet van de een op de andere dag?;vraag] [Is dit niet van tevoren aan zien te komen?;vraag] D zegt: [Tja, hier gaat natuurlijk al heel lang een discussie over.;uitspraak] [Sommige zijn van mening dat banken dit hadden moeten zien aankomen terwijl banken zeggen dat ze van niets wisten.;antwoord] [Volgens mij hebben de drie grote banken dit bewust gedaan (is later niet helemaal bewezen, maar de topmannen zijn inmiddels allemaal van het bank toneel verdwenen).;toevoeging] D zegt: [Misschien verstandig om je de bron uit te leggen?;ruis] R zegt: Ja graag D zegt: [Het Amerikaanse huizenwereldje is anders geregeld dan in Nederland. Hier in Nederland ligt alles vast in de WFT en door regels van DNB. Deze worden weer streng gecontroleerd en als banken zich hier niet aan houden kan hun banklicentie worden afgenomen. In Amerika is dit anders. Daar verkopen tussenpersonen op provisiebasis hypotheken. Deze personen konden vrij handelen. Nu moet je denken dat in Amerika de rente rondom de 1% lag. De stijging van het onroerend goed lag tussen de 10 en 20% op jaarbasis. Wat zeiden deze tussenpersonen. Laat de rente bij de schuld opvoeren. Immers, de waarde zou immers jaarlijks flink stijgen. Werkelozen en mensen met een uitkering konden op deze manier toch een hyptheek krijgen. De stijging stopte en schulden waren inmiddels zo hoop opgelopen dat mensen hun huis moesten verkopen. Banken hebben deze schulden in drie pakketjes gedaan. Veel, weinig en geen risico pakketjes. Deze zijn verzekerd doorverkocht aan kleinere banken. Je begrijpt dat uiteindelijk van deze pakketjes niet meer overbleef en de verzekering niet kon uitkeren (zoveel geld hadden ze natuurlijk niet) Dit bleek dus een schijnzekerheid te zijn...;verklaring] D zegt: [Duidelijk zo?;ruis] R zegt: Dat is helemaal duidelijk. Maar [als ik het goed begrijp wordt er door die schijnzekerheid dus gewerkt met, als ik het zo kan formuleren, 'virtueel' geld?;vraag] D zegt: [Ja en nee.;antwoord] [Het geld zat natuurlijk bij de huizenbezitters (althans in hun huis). Banken hebben toonderpapieren gebundeld en doorverkocht op de beurs. Op deze beurs kochten banken, verzekeringsmaatschappijen en beleggers deze aandelen (met geld). Dit vloeide terug naar de Amerikaanse banken... Banken, maatschappijen en sommige beleggers hadden op hun beurt weer geld geleend om deze aandelen te kunnen betalen. Immers, er zou een grote winst kunnen worden gemaakt bij verkoop. Tja, en dit laatste zorgt ervoor dat vele in de problemen zijn gekomen.;verklaring] R zegt: Oké, hoe de kredietcrisis tot stand is gekomen is mij tot zover duidelijk. Ik ga verder met de volgende vraag. De Nederlandse overheid heeft een grote rol gespeeld om dit probleem in Nederland zover mogelijk op te lossen. [Is de aankoop van Fortis bijvoorbeeld een slimme zet geweest?;vraag] D zegt: [Fortis had natuurlijk twee problemen. Enerzijds hadden liq. problemen ivm de aankoop van ABN AMRO. Hier bleken ze veel te veel voor betaald te hebben. Anderzijds hadden zo ook nog flink wat van die (waardeloze) aandelen in hun bezit. Andere handelsbanken waren bang dat Fortis de geleende gelden niet meer konden terugbetalen. Balanstechnische gezien kon het wel, echter ze hadden te weinig liquide middelen.;implicatie] [Vandaar de steun van Bos.;toevoeging] R zegt: [Is deze overname van Fortis nou juist positief of negatief voor concurrerende banken?;vraag] D zegt: [Tja, als er geen vertrouwen is, is dat natuurlijk nooit goed.;implicatie] [Van de andere kant zijn er veel klanten o.a. naar de Rabo overgekomen omdat ze geen vertrouwen hadden in hun eigen bank. Zeer zeker na het geval met Icesave.;implicatie, nuancering] [Dit laatste is dus positief voor oa. de Rabobank geweest.;implicatie, nuancering, voorbeeld] R zegt: In deze situatie heeft de overheid gegarandeert dat een hoop mensen niet voor hun spaargeld hoeven te vrezen, maar [wat nou als zo'n crisis weer een keer gebeurt? Is die zekerheid er dan weer?;vraag] D zegt: [De overheid heeft ingespeeld op de onrust in de financiele markt.;toevoeging] [Simpel,;ruis] [als banken het vertrouwen in elkaar onderling verliezen dan is het logisch dat de klant zijn of haar spaargeld weghaalt bij desbetreffende bank.;toevoeging] [Dit begon al toen ABN AMRO in de verkoop ging. Grote advertenties van Bos was het gevolg. Daarin gaf hij aan dat er 'niets' aan de hand was. Echter, dit heeft niet mogen baten zoals je inmiddels weet. Fortis en ABN AMRO kwamen daardoor in de problemen. Dit werd nog eens een keer bevestigd toen Icesave failliet ging. Als reactie gaf DNB (bij monde van Bos) aan dat alle spaargeld tot een ton verzekerd was. Dit bracht uiteindelijk wel wat rust.;toevoeging, verklaring] [De regering zal zeker niet twijfelen om dit nog een keer te doen bij een volgende keer.;antwoord] [Immers, de financiele stroom moet op gang blijven. Lees naast financiele stroom ook de economie.;verklaring] [Toch blijft de consument zijn gedrag aanpassen. Angst voor de toekomst zorgt er voor dat de consument wacht met uitgeven.;toevoeging] [Dat zie je nu al aan de huizen- en autoverkoop.;voorbeeld] [Als gevolg hiervan zijn banken ook voorzichter met het verstrekken van financieringen.;toevoeging, toevoeging] [Enerzijds omdat DNB de regels van liquiditiet voor banken heeft aangescherpt, anderzijds de voorzichtigheid met financieren aan branches waar al problemen mee zijn;toevoeging, toevoeging, verklaring] [bv. de autoindustrie.;toevoeging, toevoeging, verklaring, voorbeeld] R zegt: Ik snap het, maar [is deze angst van consumenten legitiem?;doorvraag] [Moet ik mij als student bijvoorbeeld zorgen maken?;vraag] D zegt: [De angst is niet helemaal legitiem.;antwoord] [Het is ingewikkeld, maar o.a. de media zorgen er mede voor dat de tendens negatief is.;verklaring] [Immers, als iedereen blijft lezen dat het slecht gaat gaat de consument meer sparen voor z.g.n. slechtere tijden.;verklaring, verklaring] [De rol en de invloed van de media hierin is overigens een gewild studieobject.;ruis] [De consument geeft op dit moment geen geld uit voor grotere aankopen terwijl het geld er wel is.;implicatie] [Je ziet ook dat de consument niet bespaard op bv sinterklaas- en kerstinkopen. Als ze echt geen geld hadden gehad, dan hadden ze dit zeer zeker ook niet gedaan.;implicatie, voorbeeld] [Jij als student hoeft je voorlopig nog geen zorgen te maken,;antwoord] [echter.. ;ruis] [als de situatie niet verbeterd zal op korte termijn de werkeloosheid snel stijgen en hier kun jij weer de dupe van worden als je later een baan zoekt of nu een vakantiebaantje heeft.;nuancering] [Je ziet nu al bv bij Rabo Druten dat het budget voor hulp- en vervangingskosten met enkele tonnen is gedaald. Ook het budget van marketing wordt flink naar beneden bijgesteld.;voorbeeld] [Dit heeft zeker invloed, dat kun je begrijpen.;uitspraak] R zegt: Aha, ik moet er dus wel rekening mee houden dat het mij kan tegenwerken. [Maar als ik je antwoord kort samenvat maken we ons over het algemeen druk om niets.;vraag] D zegt: [Voor de korte termijn en voor de gemiddelde particulier geldt dit inderdaad.;antwoord] [Maar... als dit langer zo blijft dan zullen de productiekosten van goederen en diensten stijgen.;nuancering] [Dit zie je als consument terug in de prijzen bij bv de supermarkt.;voorbeeld] [Ook de huizenverkoop zal teruglopen of zelfs in elkaar zakken, met alle gevolgen van dien.;voorbeeld, herhaling] [Het is zo, als de vraag naar een product hoog is, gaat de prijs stijgen.;herhaling] [Dit zie je nu ook op de kapitaalmarkt...;ruis] [De vraag naar liq.middelen is hoog, dus de rente gaat ook die kant op. Nu wordt er door de regering, IMF en DNB ingegrepen door renteverlagingen te bieden.;voorbeeld] [Zag je voorheen dat als de rente bv met 0,25 was gedaald, dit een positief effect had. Dit is inmiddels grotendeels niet meer van toepassing. Er zijn dan ook grotere rentedalingen geweest en deze hadden minimaal effect. Na de laatste rentedaling deze week is deze tendens gekeerd.;uitspraak] R zegt: Helder, ik denk dat ik een redelijk beeld heb van de huidige kredietcrisis. R zegt: daarnaast ben ik ook door mijn vragen heen :-) |
Data analyse
Chatgesprek 1
| Vraag | Efficiëntie van beantwoording |
|---|---|
| Wat is, in één zin, de kredietcrisis? | 81% |
| waarom vertrouwt niemand elkaar meer? | 75% |
| Dus niemand durft meer geld uit te lenen? | 81% |
| daardoor kunnen de banken hun leningen niet terug betalen? | 53% |
| Hoe kan de wereld van de ene dag op de andere - zo voelt het tenminste - in een crisis raken? | 51% |
| gaat de crisis mij (33, huisbezitter, beetje spaargeld) hard raken? | 90% |
| zou het kunnen dat we over een tijdje niet meer kunnen pinnen - dat scenario las ik ergens - en uit prullenbakken eten? | 77% |
| Wie moeten er wel gaan oppassen? | 62% |
| Mensen met veel geld? | 60% |
| Dus beleggen is dom? | 64% |
| nu het even slecht gaat met Fortis, neemt de Nederlanse Staat het gewoon over. Zo makkelijk. Dat kan toch niet zomaar? | 48% |
| Dat is toch niet eerlijk tegenover andere banken en bedrijven die het moeilijk hebben? | 35% |
| Wat wordt er trouwens precies bedoeld met banken die 'omvallen'? | 89% |
| Is het echt als een soort domino? | 76% |
| dat geld dat de overheid nu in de banken steekt, is dàt dan wel echt geld? | 50% |
| Is het een goed idee om wat staafjes goud in huis te halen? | 51% |
| Dus niks is veilig. Ook niet je geld in een oude sok onder je bed bewaren. | 70% |
| de overheid leent dat geld weer bij banken. HOE KAN DAT? | 45% |
| Maar hoe weet de overheid dat ze winst gaan maken op Fortis? | 15% |
| Dat geeft meteen antwoord op mijn vraag over de Boze Belgen. | 40% |
| Er worden door de overheid reusachtige bedragen gestopt in banken zoals Fortis. Wat wordt er eigenlijk met dat geld gedaan? | 85% |
| Kan de crisis ons, gewone mensen met gewone huizen en gewone inkomens, wél raken op korte termijn? | 53% |
| Maken we ons dan allemaal om niks zorgen? | 60% |
Average efficiency 61%
Chatgesprek 2
| Vraag | Efficiëntie van beantwoording |
|---|---|
| ben je klaar voor het interview? | 55% |
| Kan je me kort uitleggen wat de kredietcrisis precies is? | 40% |
| En als het vertrouwen in elkaar wegebt, hoe is dat dan een oorzaak van de crisis? | 100% |
| Wat gebeurt er dan precies? | 95% |
| een kleine schommeling waarin precies, bedoel je? | 61% |
| Dus als ik het goed begrijp begint een crisis bij de banken. Pas als de consumenten hier lucht van krijgen en angst krijgen ontstaan de echte problemen? | 47% |
| Moet ik me, als student met een beetje spaargeld, zorgen gaan maken? | 50% |
| Ik hoef me ook geen zorgen te maken dat ik op een dag niet meer kan pinnen, en uit de prullenbak moet gaan eten? | 60% |
| Maar is het wel eerlijk voor andere banken dat de regering bijvoorbeeld Fortis ineens lijkt te helpen? | 41% |
| Maar die hebben er waarschijnlijk ook weer baat bij, dat de regering het land uit de crisis probeert te halen? | 67% |
| Ik hoorde een econoom zeggen dat het misschien slim is wat staafjes goud aan te schaffen. Zit hier iets in? | 60% |
| Of moet ik geld gewoon in een sok gaan bewaren? | 100% |
| Kan ik uit dit interview concluderen dat de man van de straat eigenlijk zich zorgen maakt om niets? | 53% |
| Ok, angst is dus ook in deze een slechte raadgever.... | 40% |
Average efficiency 62%
Chatgesprek 3
| Vraag | Efficiëntie van beantwoording |
|---|---|
| wat is de kredietcrisis? | 70% |
| En hoe onstaat dat vertrouwensverlies van banken onderling? | 75% |
| zoiets gebeurt toch niet van de een op de andere dag? | 51% |
| Is dit niet van tevoren aan zien te komen? | 53% |
| als ik het goed begrijp wordt er door die schijnzekerheid dus gewerkt met, als ik het zo kan formuleren, 'virtueel' geld? | 85% |
| Is de aankoop van Fortis bijvoorbeeld een slimme zet geweest? | 50% |
| Is deze overname van Fortis nou juist positief of negatief voor concurrerende banken? | 54% |
| wat nou als zo'n crisis weer een keer gebeurt? Is die zekerheid er dan weer? | 44% |
| is deze angst van consumenten legitiem? | 61% |
| Moet ik mij als student bijvoorbeeld zorgen maken? | 74% |
| Maar als ik je antwoord kort samenvat maken we ons over het algemeen druk om niets. | 56% |
Average efficiency 61%
Datamodel
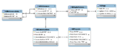
datamodel
Uitleg:
Je begint met het aanmaken van een project, deze gegevens worden opgeslagen in 'tblProjects', bijv. "OZM2". Vervolgens kunnen er aan dat project conversaties worden toegevoegd, bijv. "Chatgesprek 1". Deze worden opgeslagen in 'tblConversations'. In het veld 'ConversationRawData' komt het gehele interview inclusief tags te staan. De 'tblReferences' wordt gevuld met de losse referenties, zonder de tekens die voor syntax van belang zijn. Daarna kan er in 'tblTagReference' een link gelegd worden zodat daar uit af te lezen is welke tagnaam/tagnamen er bij een referentie is/zijn geplaatst. Deze tabel heeft geen primary keys omdat het mogelijk is dat er als volgt getagged wordt: [tekst;nuancering,nuancering]. Deze tekst is dus een nuancering van een voorgaande nuancering. Dat betekent een dubbele entry in 'tblTagReference', vandaar dat deze tabel geen primary keys bevat. In 'tblTags' staan alle verschillende tags (zowel vraag als antwoord tags) inclusief hun waarde van 0,0 tot 1,0. Als laatste moet 'tblReferenceLinks' worden gevuld waar een link wordt gelegd tussen alle vraagtags met hun bijbehorende beantwoording. Een vraag kan namelijk bestaan uit bijvoorbeeld een nuancering, verklaring, antwoord en toevoeging. Dat deze allemaal bij 1 vraag horen wordt hier gekoppeld.
| MySQL script inclusief Stored Procedures |
|---|
|
TextAnalyzer.sql SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0; SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0; SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='TRADITIONAL'; CREATE SCHEMA IF NOT EXISTS `myDB` DEFAULT CHARACTER SET latin1 COLLATE latin1_swedish_ci ; USE `myDB`; -- ----------------------------------------------------- -- Table `myDB`.`tblProjects` -- ----------------------------------------------------- DROP TABLE IF EXISTS `myDB`.`tblProjects` ; CREATE TABLE IF NOT EXISTS `myDB`.`tblProjects` ( `ProjectID` INT NOT NULL AUTO_INCREMENT , `ProjectName` VARCHAR(45) NOT NULL , `ProjectDate` DATE NOT NULL , `ProjectAuthor` VARCHAR(45) NOT NULL , `ProjectDescription` TEXT NOT NULL , PRIMARY KEY (`ProjectID`) ) ENGINE = MyISAM; -- ----------------------------------------------------- -- Table `myDB`.`tblConversations` -- ----------------------------------------------------- DROP TABLE IF EXISTS `myDB`.`tblConversations` ; CREATE TABLE IF NOT EXISTS `myDB`.`tblConversations` ( `ConversationID` INT NOT NULL AUTO_INCREMENT , `ProjectID` INT NOT NULL , `ConversationName` VARCHAR(45) NOT NULL , `ConversationDate` DATE NOT NULL , `ConversationRawData` LONGTEXT NOT NULL , PRIMARY KEY (`ConversationID`) , INDEX `fk_tblConversations_tblProjects` (`ProjectID` ASC) , CONSTRAINT `fk_tblConversations_tblProjects` FOREIGN KEY (`ProjectID` ) REFERENCES `myDB`.`tblProjects` (`ProjectID` ) ON DELETE NO ACTION ON UPDATE NO ACTION) ENGINE = MyISAM; -- ----------------------------------------------------- -- Table `myDB`.`tblReferences` -- ----------------------------------------------------- DROP TABLE IF EXISTS `myDB`.`tblReferences` ; CREATE TABLE IF NOT EXISTS `myDB`.`tblReferences` ( `ReferenceID` INT NOT NULL AUTO_INCREMENT , `ConversationID` INT NOT NULL , `ReferenceData` LONGTEXT NOT NULL , PRIMARY KEY (`ReferenceID`) , INDEX `fk_tblReferences_tblProjects` (`ConversationID` ASC) , CONSTRAINT `fk_tblReferences_tblProjects` FOREIGN KEY (`ConversationID` ) REFERENCES `myDB`.`tblConversations` (`ConversationID` ) ON DELETE NO ACTION ON UPDATE NO ACTION) ENGINE = MyISAM; -- ----------------------------------------------------- -- Table `myDB`.`tblTags` -- ----------------------------------------------------- DROP TABLE IF EXISTS `myDB`.`tblTags` ; CREATE TABLE IF NOT EXISTS `myDB`.`tblTags` ( `TagID` INT NOT NULL AUTO_INCREMENT , `TagName` VARCHAR(45) NOT NULL , `TagValue` DECIMAL(2,1) NOT NULL , PRIMARY KEY (`TagID`) ) ENGINE = MyISAM; -- ----------------------------------------------------- -- Table `myDB`.`tblTagReference` -- ----------------------------------------------------- DROP TABLE IF EXISTS `myDB`.`tblTagReference` ; CREATE TABLE IF NOT EXISTS `myDB`.`tblTagReference` ( `ReferenceID` INT NOT NULL , `TagID` INT NOT NULL , INDEX `fk_tblTagReference_tblReferences` (`ReferenceID` ASC) , INDEX `fk_tblTagReference_tblTags` (`TagID` ASC) , CONSTRAINT `fk_tblTagReference_tblReferences` FOREIGN KEY (`ReferenceID` ) REFERENCES `myDB`.`tblReferences` (`ReferenceID` ) ON DELETE NO ACTION ON UPDATE NO ACTION, CONSTRAINT `fk_tblTagReference_tblTags` FOREIGN KEY (`TagID` ) REFERENCES `myDB`.`tblTags` (`TagID` ) ON DELETE NO ACTION ON UPDATE NO ACTION) ENGINE = MyISAM; -- ----------------------------------------------------- -- Table `myDB`.`tblReferenceLinks` -- ----------------------------------------------------- DROP TABLE IF EXISTS `myDB`.`tblReferenceLinks` ; CREATE TABLE IF NOT EXISTS `myDB`.`tblReferenceLinks` ( `ReferenceID1` INT NOT NULL , `ReferenceID2` INT NOT NULL , PRIMARY KEY (`ReferenceID1`, `ReferenceID2`) , INDEX `fk_tblReferenceLinks_tblReferences` (`ReferenceID1` ASC) , INDEX `fk_tblReferenceLinks_tblReferences1` (`ReferenceID2` ASC) , CONSTRAINT `fk_tblReferenceLinks_tblReferences` FOREIGN KEY (`ReferenceID1` ) REFERENCES `myDB`.`tblReferences` (`ReferenceID` ) ON DELETE NO ACTION ON UPDATE NO ACTION, CONSTRAINT `fk_tblReferenceLinks_tblReferences1` FOREIGN KEY (`ReferenceID2` ) REFERENCES `myDB`.`tblReferences` (`ReferenceID` ) ON DELETE NO ACTION ON UPDATE NO ACTION) ENGINE = MyISAM; DELIMITER // DROP procedure IF EXISTS `myDB`.`Conversation_Insert` // CREATE PROCEDURE `Conversation_Insert`(IN paramProjectID INT, IN paramConversationName varchar(45), IN paramConversationDate date, IN paramConversationRawData longtext) BEGIN INSERT INTO tblConversations (ProjectID, ConversationName, ConversationDate, ConversationRawData) VALUES (paramProjectID, paramConversationName, paramConversationDate, paramConversationRawData); SELECT @@IDENTITY; END // DROP procedure IF EXISTS `myDB`.`DataByReferenceID_Select` // CREATE PROCEDURE `DataByReferenceID_Select`(IN paramReferenceID1 INT) BEGIN SELECT rl.ReferenceID1, rl.ReferenceID2, t.TagID, (SELECT SUM(length(r.ReferenceData) + 1 - length(REPLACE(r.ReferenceData,' ',))) FROM tblReferences r WHERE r.ReferenceID = rl.ReferenceID2) AS WordCount FROM tblReferenceLinks rl LEFT JOIN tblTagReference tr ON tr.ReferenceID = rl.ReferenceID2 LEFT JOIN tblTags t ON tr.TagID = t.TagID WHERE rl.ReferenceID1 = paramReferenceID1 GROUP BY rl.ReferenceID2; END // DROP procedure IF EXISTS `myDB`.`Project_Insert` // CREATE PROCEDURE `Project_Insert`(IN paramProjectName varchar(45), IN paramProjectDate date, IN paramProjectAuthor varchar(45), IN paramProjectDescription text) BEGIN INSERT INTO tblProjects (ProjectName, ProjectDate, ProjectAuthor, ProjectDescription) VALUES (paramProjectName, paramProjectDate, paramProjectAuthor, paramProjectDescription); SELECT @@IDENTITY; END // DROP procedure IF EXISTS `myDB`.`QuestionsByConversationID_Select` // CREATE PROCEDURE `QuestionsByConversationID_Select`(IN paramConversationID INT) BEGIN SELECT c.ConversationName, r.ReferenceID, r.ReferenceData, t.TagID, t.TagName FROM tblReferences r LEFT JOIN tblConversations c ON r.ConversationID = c.ConversationID LEFT JOIN tblTagReference tr ON r.ReferenceID = tr.ReferenceID LEFT JOIN tblTags t ON tr.TagID = t.TagID WHERE r.ConversationID = paramConversationID AND t.TagID BETWEEN 10 AND 12 ORDER BY r.ReferenceID, t.TagID; END // DROP procedure IF EXISTS `myDB`.`Reference_Insert` // CREATE PROCEDURE `Reference_Insert`(IN paramConversationID int, IN paramReferenceData longtext) BEGIN INSERT INTO tblReferences (ConversationID, ReferenceData) VALUES (paramConversationID, paramReferenceData); SELECT @@IDENTITY; END // DROP procedure IF EXISTS `myDB`.`Reference_Select` // CREATE PROCEDURE `Reference_Select`(IN paramConversationID INT) BEGIN SELECT r.ReferenceID, r.ReferenceData, t.TagID, t.TagName FROM tblReferences r LEFT JOIN tblTagReference tr ON r.ReferenceID = tr.ReferenceID LEFT JOIN tblTags t ON tr.TagID = t.TagID WHERE r.ConversationID = paramConversationID ORDER BY r.ReferenceID, t.TagID; END // DROP procedure IF EXISTS `myDB`.`ReferenceLink_Insert` // CREATE PROCEDURE `ReferenceLink_Insert`(IN paramReferenceID1 int, IN paramReferenceID2 int) BEGIN INSERT INTO tblReferenceLinks (ReferenceID1, ReferenceID2) VALUES (paramReferenceID1, paramReferenceID2); END // DROP procedure IF EXISTS `myDB`.`ReferenceLinked_Select` // CREATE PROCEDURE `ReferenceLinked_Select`(IN paramReferenceID INT) BEGIN SELECT COUNT(*) AS ReferenceLinked FROM tblReferenceLinks WHERE ReferenceID1 = paramReferenceID OR ReferenceID2 = paramReferenceID; END // DROP procedure IF EXISTS `myDB`.`ReferenceWordCountByConversationID_Select` // CREATE PROCEDURE `ReferenceWordCountByConversationID_Select`(IN paramConversationID INT) BEGIN SELECT r.*, SUM(length(r.ReferenceData) + 1 - length(REPLACE(r.ReferenceData,' ',))) AS WordCount FROM tblReferences r LEFT JOIN tblTagReference tr ON r.ReferenceID = tr.ReferenceID LEFT JOIN tblTags t ON tr.TagID = t.TagID WHERE r.ConversationID = paramConversationID AND t.TagID BETWEEN 2 AND 9 GROUP BY r.ReferenceID ORDER BY r.ReferenceID, t.TagID; END // DROP procedure IF EXISTS `myDB`.`TagReference_Insert` // CREATE PROCEDURE `TagReference_Insert`(IN paramReferenceID int, IN paramTagName varchar(45)) BEGIN INSERT INTO tblTagReference (ReferenceID, TagID) VALUES (paramReferenceID, (SELECT TagID FROM tblTags WHERE TagName = paramTagName)); END // DROP procedure IF EXISTS `myDB`.`TagsByConversationID_Select` // CREATE PROCEDURE `TagsByConversationID_Select`(IN paramConversationID INT) BEGIN SELECT r.* FROM tblReferences r LEFT JOIN tblTagReference tr ON r.ReferenceID = tr.ReferenceID LEFT JOIN tblTags t ON tr.TagID = t.TagID WHERE r.ConversationID = paramConversationID AND t.TagID BETWEEN 2 AND 9 GROUP BY r.ReferenceID; END // DROP procedure IF EXISTS `myDB`.`TagValueByReferenceID_Select` // CREATE PROCEDURE `TagValueByReferenceID_Select`(IN paramReferenceID INT) BEGIN SELECT r.ReferenceID, t.TagID, t.TagValue FROM tblReferences r LEFT JOIN tblTagReference tr ON tr.ReferenceID = r.ReferenceID LEFT JOIN tblTags t ON tr.TagID = t.TagID WHERE r.ReferenceID = paramReferenceID; END // DELIMITER ; USE `myDB`; -- ----------------------------------------------------- -- Data for table `myDB`.`tblTags` -- ----------------------------------------------------- SET AUTOCOMMIT=0; INSERT INTO `tblTags` (`TagID`, `TagName`, `TagValue`) VALUES (1, 'Ruis', 0.0); INSERT INTO `tblTags` (`TagID`, `TagName`, `TagValue`) VALUES (2, 'Herhaling', 0.1); INSERT INTO `tblTags` (`TagID`, `TagName`, `TagValue`) VALUES (3, 'Uitspraak', 0.2); INSERT INTO `tblTags` (`TagID`, `TagName`, `TagValue`) VALUES (4, 'Toevoeging', 0.4); INSERT INTO `tblTags` (`TagID`, `TagName`, `TagValue`) VALUES (5, 'Implicatie', 0.6); INSERT INTO `tblTags` (`TagID`, `TagName`, `TagValue`) VALUES (6, 'Verklaring', 0.7); INSERT INTO `tblTags` (`TagID`, `TagName`, `TagValue`) VALUES (7, 'Nuancering', 0.9); INSERT INTO `tblTags` (`TagID`, `TagName`, `TagValue`) VALUES (8, 'Voorbeeld', 0.9); INSERT INTO `tblTags` (`TagID`, `TagName`, `TagValue`) VALUES (9, 'Antwoord', 1.0); INSERT INTO `tblTags` (`TagID`, `TagName`, `TagValue`) VALUES (10, 'Vraag', 1.0); INSERT INTO `tblTags` (`TagID`, `TagName`, `TagValue`) VALUES (11, 'Doorvraag', 1.0); COMMIT; SET SQL_MODE=@OLD_SQL_MODE; SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS; SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS; |
Source code
| C# funtionheaders |
|---|
|
C# functionheaders /* <summary>Database helper to execute a non query</summary> ** ** <param>commandText: a string value which represents the name of the stored procedure</param> ** <param>commandparameters: a string value which represents the name of the stored procedure</param> ** <return>The first column of the first row in the result set of the returned by the stored procedure</return> */ public static int ExecuteNonQuery(string commandText, params OdbcParameter[] commandParameters)
/* <summary>Database helper to execute a dataset</summary> ** ** <param>commandText: a string value which represents the name of the stored procedure</param> ** <param>commandparameters: a string value which represents the name of the stored procedure</param> ** <return>Dataset of the result set, returned by the stored procedure</return> */ public static DataSet ExecuteDataset(string commandText, params OdbcParameter[] commandParameters)
/* <summary>Button event handler to save a project</summary> ** ** <param>sender: the asp.net caller object</param> ** <param>e: the event arguments of the asp.net caller object</param> ** <return></return> */ protected void saveProject_OnClick(object sender, EventArgs e)
/* <summary>Button event handler to save a conversation</summary> ** ** <param>sender: the asp.net caller object</param> ** <param>e: the event arguments of the asp.net caller object</param> ** <return></return> */ protected void saveConversation_OnClick(object sender, EventArgs e)
/* <summary>Button event handler to link references to a question</summary> ** ** <param>sender: the asp.net caller object</param> ** <param>e: the event arguments of the asp.net caller object</param> ** <return></return> */ protected void btnReferenceListNextQuestion_OnClick(object sender, EventArgs e)
/* <summary>Button event handler to link references to the last question and view the results</summary> ** ** <param>sender: the asp.net caller object</param> ** <param>e: the event arguments of the asp.net caller object</param> ** <return></return> */ protected void btnReferenceListViewResults_OnClick(object sender, EventArgs e)
/* <summary>Function thato stores a given reference with the current conversation in the database</summary> ** ** <param>sReference: a string value which represents the reference data</param> ** <return>The ReferenceID of the stored reference</return> */ private int saveReferenceToDb(string sReference)
/* <summary>Function that stores a given referenceID and tagname in the database</summary> ** ** <param>referenceID: an integer value which represents the reference</param> ** <param>sTag: a string value which represents the tagname</param> ** <return></return> */ private void saveTagReferenceToDb(int referenceID, string sTag)
/* <summary>Function that stores a given referenceID and the referenceID of the current question in the database</summary> ** ** <param>referenceID: an integer value which represents the reference</param> ** <return></return> */ private void saveReferenceLinkToDb(int referenceID)
/* <summary>Function to check wether a given referenceID is linked to a question</summary> ** ** <param>referenceID: an integer value which represents the reference</param> ** <return>A boolean wether the given referenceID is linked to a question</return> */ private bool referenceLinked(int referenceID)
/* <summary>Function that calculates the efficiency value of a given reference</summary> ** ** <param>referenceID: an integer value which represents the reference</param> ** <return>A decimal with the calculated efficiency value</return> */ protected decimal getTagValueByReferenceID(int referenceID)
/* <summary>Function that queries the database and get the corresponding data of a given reference</summary> ** ** <param>referenceID: an integer value which represents the reference</param> ** <return>A dataset of the reference data</return> */ protected DataSet getDataByReferenceID(int referenceID)
/* <summary>Function that queries the database to get the total amount of tags used in a conversation</summary> ** ** <param></param> ** <return>A decimal with the total amount of tags used in the conversation</return> */ protected decimal getTotalTagCount()
/* <summary>Function that queries the database to get the total amount of words used in a conversation</summary> ** ** <param></param> ** <return>A decimal with the total amount of words used in the conversation</return> */ protected decimal getTotalWordCount()
/* <summary>Function that parses the raw, tagged conversation and stores it into the database</summary> ** ** <param>rawData: a string value with the raw, tagged conversation</param> ** <return></return> */ private void parseConversation(string rawData)
/* <summary>Function that builds the webcontrols for linking references to questions</summary> ** ** <param></param> ** <return></return> */ private void buildReferenceLinks() /* <summary>Function that builds the results and calculates the average efficienty of a conversation</summary> ** ** <param></param> ** <return></return> */ private void buildResults() |
Conclusie
In ons onderzoek heeft voornamelijk de ontwikkeling van de methoden centraal gestaan, dit gedeelte was ook het meest tijdrovend. In een verbetertraject, of watervalmethode, hebben we geschaafd en veranderd aan de methode, zodat we de uiteindelijke kwaliteit van de methoden zo hoog mogelijk hebben gekregen binnen het vooraf vastgelegde tijdsbestek. Datgene wat we hiervoor ontwikkeld hebben is een compleet instrument waarmee de uiteindelijke analyse in een zeer hoog tempo en op consistente wijze uitgevoerd kan worden. Dit levert de mogelijkheid op om in vervolgonderzoek wanneer je interviews van een andere aard zou willen vergelijken met deze uitkomst dit instrument weer te gebruiken. Dit zal weinig tijd kosten en het resultaat is gebaseerd op exact gelijke methoden.
De onderzoeksvraag die wij ons gesteld hebben is "Hoe efficiënt worden vragen beantwoord in een interview middels een chatgesprek?". Deze vraag is in een zeer concrete vorm beantwoord door middel van een waarde. Deze waren voor de drie gesprekken respectievelijk 61%, 62% en 61%. Het feit dat deze waarden zo dicht bij elkaar liggen draagt bij aan de waarde van de uitkomst van dit onderzoek. Op basis van deze drie gesprekken kunnen we stellen dat de efficientie van het beantwoorden van vragen in een interview middels een chatgesprek rond de 60% ligt. Wij beoordelen dit als redelijk efficient. Hierbij wel gezegd dat je hier pas zinnigere uitspraken over kan doen wanneer je de efficientie van beantwoorden in een interview middels andere methoden weet te achterhalen, berekend op basis van gelijke methodiek. Maar de vraag uit dit onderzoek achten wij als beantwoord in de vorm van de zojuist gegeven percentuele waarden.
In ons onderzoek zijn verbeteringen aan te brengen om tot een nog secuurdere berekening van de efficientie te komen. Bijvoorbeeld is dat datgene wat we met de ruis hebben gedaan, het wegen van de hoeveelheid van de ruis, ook toegepast kan worden op alle andere tags. Een voorbeeld van wat de uitslag slecht kan beinvloeden als je dit niet met alle tags doet, is dat wanneer iemand een korte, maar helder en complete verklaring geeft voor een beantwoording, dit dezelfde efficientiewaarde oplevert als wanneer iemand een hele lange maar ook complete verklaring geeft voor dezelfde beantwoording. Dit terwijl je zou kunnen zeggen dat wanneer je met minder woorden iets kan zeggen, dit altijd efficienter is. Door alle type tags dus vooraf te wegen, zoals ook bij het ruisvoorbeeld het geval is, kan je dit probleem ondervangen.
Tijdens ons onderzoek zijn we ergens tegenaan gelopen waardoor we op het idee zijn gekomen voor een ander onderzoeksonderwerp, wat de uitkomsten nog meer waarde kan geven. Zo is het ons opgevallen dat er soms op een slechte wijze vragen worden gesteld, waardoor het voor de geinterviewde soms onmogelijk is met een efficiente beantwoording te komen. Dit komt bijvoorbeeld voor wanneer de interviewer een veronderstelling doet die niet correct is. Wanneer een interviewer bijvoorbeeld vraagt "Waarom heeft u gekozen voor koffie?", terwijl de ondervraagde juist een kopje thee drinkt, kan hij deze vraag niet efficient beantwoorden. Wanneer hij zegt dat hij hier niet voor heeft gekozen geeft hij weliswaar de situatie weer, maar dit is geen direct antwoord op de gestelde vraag. Dit is dan een uitspraak over de vraag.
Omdat we dit probleem signaleerde, concludeerden we dat een onderzoek naar de effectiviteit van de vraagstelling nodig is om ook de variabelen in de vraagstellingen glad te strijken. Wanneer dit gebeurt is een uitspraak over de efficientie van beantwoordingen middels een bepaalde methode waardevoller met betrekking tot die methode.
Bijlage
Hieronder het chatgesprek tussen Aaf Brandt Corstius en Egbert Kalse uit de NRC Next.
E: Egbert Kalse
A: Aaf Brandt Cortius
| Chatgesprek1 |
|---|
|
E zegt: Ha Aaf A zegt: Hoi Egbert, daar ben ik, met vraag 1: Wat is, in één zin, de kredietcrisis? E zegt: Een crisis in de financiële wereld waardoor niemand elkaar meer vertrouwt, dat is eigenlijk de simpelste uitleg. A zegt: En waarom vertrouwt niemand elkaar meer? E zegt: Omdat niemand meer van elkaar weet hoeveel risico de ander loopt. Simpel voorbeeldje: als jij je geld uitleent aan een vriendin van wie je niet weet of ze al diep in de schulden zit, dan aarzel jij neem ik aan ook om dat geld uit te lenen. Dat werkt bij banken net zo. A zegt: Dus niemand durft meer geld uit te lenen? E zegt: Nee, en dat komt omdat al die banken hebben belegd in waanzinnig ingewikkelde producten. Die zijn zo ingewikkeld, dat de banken vaak zelf niet meer weten welk risico ze daarmee lopen. Weer een simpel voorbeeldje: banken hebben allemaal (en dan bedoel ik ook echt allemaal) belegd in obligaties waar Amerikaanse hypotheken als onderpand dienen. Nu in Amerika de huizenprijzen de kelderen en mensen uit hun huizen worden gezet en hun hypotheken niet meer kunnen betalen, raakt dat dus alle banken. A zegt: Dus nog even samengevat, door mij, als nitwit. De banken hebben huizen als onderpand gebruikt. Maar de huizenprijzen kelderen. Dus de huizen zijn niks meer waard. En daardoor kunnen de banken hun leningen niet terug betalen? Sorry hoor, maar het is best mysterieus allemaal. E zegt: Dat is het ook, maar je samenvatting klopt! Jij vraagt je natuurlijk af waarom jouw bank in Nederland in hemelsnaam in Amerikaanse hypotheken gaat beleggen? Dat komt omdat ze dachten daar meer geld mee te kunnen verdienen dan met andere beleggingen. Iedereen (dan bedoel ik voor de verandering maar weer eens echt iedereen) dacht dat de huizenprijzen in Amerika altijd zouden blijven stijgen. Dom natuurlijk, maar zo was het wel. En omdat iedereen dat dacht, dacht ook iedereen dat het wel veilig was daarin te beleggen. Niet dus. A zegt: O! Oké, dat is duidelijk. Dan nu een andere vraag. Hoe kan de wereld van de ene dag op de andere - zo voelt het tenminste - in een crisis raken? E zegt: Ja, dat is fascinerend. Het heeft alles te maken met angst. Maar eerst even dit: de kredietcrisis is alweer 14, 15 maanden bezig, maar tot nu toe leek het een probleem dat zich vooral bij Amerikaanse zakenbanken afspeelde en een paar Europese banken die heel veel hadden belegd in Amerikaanse hypotheken. Maar ja, beleggers zijn ook mensen en als de crisis maar lang genoeg aanhoudt, raakt op een gegeven moment iedereen in paniek. Mensen gaan dan echt letterlijk wegrennen van hun beleggingen. Je zag het twee weken geleden op maandag: niemand had nergens meer vertrouwen in, de aandelenbeurzen kelderden en, erger nog, mensen begonnen hun geld weg te halen bij hun banken. En dan is het pas echt crisis. A zegt: Ik voel de paniek inmiddels zelf ook een beetje. Daarom een paar vragen: gaat de crisis mij (33, huisbezitter, beetje spaargeld) hard raken? E zegt: Dat denk ik eerlijk gezegd niet, althans, niet op hele korte termijn. Jij hebt een huis en dus een hypotheek. Als je de afspraak hebt dat die bijvoorbeeld de komende 5 jaar een vaste rente heeft, blijf jij dus gewoon elke maand datzelfde bedrag aan je bank betalen. Er even vanuit gaande dat je een inkomen blijft houden, moet dat dus geen probleem opleveren. Wat je nooit kunt weten is, hoe hoog de rente zal zijn als je huidige periode afloopt en je een nieuwe afspraak moet maken met je bank. Die onzekerheid heb je altijd, crisis of niet. Je spaargeld staat veilig, sterker nog, dat wordt nog beter. De Staat garandeert je ongeveer 38.000 euro als je bank failliet zou gaan en while we Skype is minister Bos in Brussel bezig om dat bedrag nog op te hogen. Zolang je minder dan 40.000 euro op de bank hebt, is er dus geen enkel probleem. A zegt: En zou het kunnen dat we over een tijdje niet meer kunnen pinnen - dat scenario las ik ergens - en uit prullenbakken eten? E zegt: Ook dat valt wel mee. Nederland kent 4 grote banken, ABN, Fortis, ING en Rabobank, en die zijn allemaal zo belangrijk voor het functioneren van de Nederlandse maatschappij dat de Staat die nooit zal laten omvallen (kijk maar wat er dit weekende met Fortis en ABN gebeurde, gewoon gered door minister Bos). Aan jouw leven verandert weinig. Kijk, als de crisis lang aanhoudt kan het natuurlijk wel zo zijn dat ook de reële economie (die waar jij en ik iedere dag in rond lopen) er wat van gaat merken. Bedrijven hebben geen geld meer om bijvoorbeeld uit te breiden (kan ook de kaaszaak bij jou op de hoek zijn). Of de werkeloosheid loopt op, waardoor het moeilijker wordt om aan een baan te komen. Maar het is nu nog heel moeilijk in te schatten of, en zo ja hoe erg dat als gevolg van deze crisis zal toeslaan. A zegt: Wie moeten er wel gaan oppassen? Mensen met veel geld? E zegt: Ja, die hebben een wat groter probleem, zou je kunnen zeggen. Ten minste als ze meer dan 40.000 euro op de bank hebben staan, dan wordt dat meerdere niet vergoed als het fout gaat. En beleggers moeten helemaal oppassen natuurlijk. Daar geldt een hele andere grens. Logisch ook, je zou het in tijden van economische voorspoed bijna vergeten, maar beleggen is een vorm van risico nemen. De mensen die in Fortis hebben belegd, zijn weer even met de neus op de feiten gedrukt. Hun aandelen zijn nog maar iets van 4 euro per stuk waard, een jaar geleden nog ruim 30 euro per stuk. Jammer maar helaas, hadden ze het maar op hun spaarbank moeten zetten. A zegt: Dus beleggen is dom? E zegt: Beleggen is risico nemen. En wie risico neemt, kan zijn geld kwijtraken. A zegt: Wat ik niet snap: een bank is een commerciële instelling. En nu het even slecht gaat met Fortis, neemt de Nederlanse Staat het gewoon over. Zo makkelijk. Dat kan toch niet zomaar? Dat is toch niet eerlijk tegenover andere banken en bedrijven die het moeilijk hebben? E zegt: Wees blij, zou ik in dit geval zeggen. Als de staat niet had geholpen, was Fortis echt omgevallen (failliet gegaan). En dan waren niet alleen een heleboel mensen gedupeerd (zij die meer dan 40.000 op de bank hadden staan bijvoorbeeld), maar waren er ook een hoop werkelozen bij gekomen en liepen al die andere banken, die van en aan Fortis geld hadden uitgeleend, grote risico's. Dat is wat Nout Wellink van De Nederlandse Bank een 'systeemrelevante bank' noemt: cruciaal voor het functioneren van de Nederlandse geldmarkt. Maar je hebt wel een punt hoor, waarom redden ze die bank wel als het mis gaat en bijvoorbeeld die kaasboer bij jou op de hoek niet. Het ergste van alles is dat banken daar ook op rekenen, dat ze worden gered als het mis gaat. Nog een keer die kaasboer: die zorgt ervoor dat hij een potje achter de hand heeft voor als het even tegenzit. Keurig, met gezond verstand ondernemen, wat mij betreft. Maar die banken, die hebben amper geld achter de hand als het mis gaat. Die redeneren als volgt: als we vallen, komt de overheid ons wel helpen. Dus tot die tijd hoeven we nergens rekening mee te houden en kunnen we lekker geld verdienen! A zegt: Wat een boeven eigenlijk. Wat wordt er trouwens precies bedoeld met banken die 'omvallen'? Is het echt als een soort domino? Dat de ene bank de andere bank meesleept in zijn val? E zegt: Een beetje wel, zoals ik net al zei, al die banken lenen geld van en aan elkaar. Als er eentje gaat, loopt de rest het risico ook te gaan. Daarom vertrouwen ze elkaar ook niet meer en is de markt van onderling aan elkaar lenen opgedroogd, zoals dat heet. En omvallen is een alternatief voor falliet gaan. Al gebruiken wij omvallen ook weleens als een soort voorportaal van een faillissement. De Amerikaanse zakenbank Bear Stearns viel in maart dit jaar om, maar werd opgekocht. De Amerikaanse zakenbank Lehman Brothers viel om en ging ook echt failliet (in september was dat). A zegt: Wat ik ook zo'n wonderlijk geval vind, is virtueel geld. Geld dat er eigenlijk niet is. Banken hébben helemaal niet al dat geld dat de rekeninghouders daar hebben neergezet, lees ik. Het is 'virtueel geld'. En daarom moeten we vooral niet met z'n allen naar de bank lopen om ons geld op te nemen, want dat ís er dan niet. Maar dat geld dat de overheid nu in de banken steekt, is dát dan wel echt geld? E zegt: Al het geld is echt, zolang wij daarin geloven. Heeeeeeel vroeger was er voor elke gulden (je weet wel) bepaalde hoeveelheid goud, zodat je altijd je gulden in kon ruilen voor dat goud. Daar zijn we allang vanaf gestapt, en nu is het zo dat de staat degene is die bepaald wat de waarde van het geld is. Normaal gesproken gaat dat redelijk goed. Elk jaar komt er een beetje geld bij, soms wat meer dan de producten die we maken (dat heet dat inflatie). Maar soms gaat het ook helemaal mis (zoek maar eens op Google naar Zimbabwe en inflatie). A zegt: Nog even over het geld. Ik las dat er een econoom is die liever goud dan geld in huis heeft. Omdat goud niet in waarde kan verminderen. Is het een goed idee om wat staafjes goud in huis te halen? E zegt: Goud wordt nog steeds gezien als een zeer waardevaste vorm van beleggen. Maar zoals het woord al zegt, het blijft een belegging. Omdat goud van oorsprong de functie had van maatstaf voor al het geld, vluchten beleggers nog steeds in goud als het fout gaat met de rest van de aandelen. Maar ook de goudprijs kan enorm schommelen, dus je moet niet raar opkijken als je nu zeg 1.000 euro omzet in goudstaven (ik geloof dat je dan iets van 35 gram kunt kopen nu) en dat over een half jaar datzelfde goud nog maar 700 euro waard is. Ook hier geldt: geen garanties! A zegt: Dus niks is veilig. Ook niet je geld in een oude sok onder je bed bewaren. E zegt: Als je een goede inbraakbeveiliging hebt, is dat veilig. Alleen wordt dat geld elk jaar relatief minder waard (vanwege de inflatie). A zegt: Ja, dat bedoelde ik. Dat al dat geld misschien straks niks meer waard is. Nog een vraag. Banken hebben geld tekort. Begrijp ik. De overheid steekt er nu veel geld in. Begrijp ik ook. Maar de overheid leent dat geld weer bij banken. HOE KAN DAT? Van dit soort zaken wordt een niet-econoom helemaal wanhopig... E zegt: Ha ha, ja, dat lijkt vreemd inderdaad. Maar ik kan het (hoop ik) uitleggen. De Nederlandse overheid heeft nu bijvoorbeeld 16,8 miljard euro betaald voor Fortis. Als ze dat geld zelf zouden bijdrukken, vliegt de inflatie omhoog (het is ruim 3 procent van wat we in Nederland in een jaar verdienen!). Wat ze dus doen is het geld lenen, zodat de staatsschuld omhoog gaat. Dat geld lenen ze vaak bij andere overheden, maar ook bij banken, verzekeraars, pensioenfondsen, of multinationals. En de overheid is dankzij de kreditietcrisis enorm populair geworden om geld aan uit te lenen. Immers: de overheid kan niet failliet. Een bank die geld op zijn balans leent (is oude sok) en er toch nog iets op wil verdienen, leent het dus liever uit aan de overheid voor een rente van zeg 3 procent, dan dat-ie het aan een andere bank uitleent voor zeg 5 procent. A zegt: Mijn hersens kraken op dit moment. E zegt: Ze kopen er ook een hele bank voor, de overheid is nu de eigenaar van Fortis. En als ze dat later weer verkopen, hebben ze weer geld om die leningen af te lossen. A zegt: Maar hoe weet de overheid dat ze winst gaan maken op Fortis? E zegt: Dat weet de overheid niet zeker, het is een belegging en zoals ik al zei: Beleggen brengt risico's met zich mee. Echter, de kans dat ze er winst op maken is best groot. De Nederlandse overheid heeft namelijk keihard met de Belgen onderhandeld over de prijs. Belgie wilde veel meer geld hebben voor ABN Amro, Fortis Nederland en Fortis Nederland verzekeringen. Maar dat lieten Bos, Balkenende en Wellink niet gebeuren. Zij zagen ook dat de Belgen redelijk wanhopig op zoek waren naar geld om de rest van Fortis overeind te houden. Dat gaf Nederland een goede positie om te onderhandelen. Als de crisis voorbij is (niet vragen hoelang dat nog duurt, dat weet ik echt niet en niemand weet dat), kan Nederland eens rustig kijken aan wie ze de bank willen verpatsen. Voor een mooie prijs het liefst. A zegt: Sluw! Die Nederlandse overheid toch. Dat geeft meteen antwoord op mijn vraag over de Boze Belgen. E zegt: Die waren ook nog boos omdat Bos had gezegd dat de Belgen met het slechte deel van Fortis bleven zitten. Dat klopt wel, maar is niet zo netjes om te zeggen. A zegt: Er worden door de overheid reusachtige bedragen gestopt in banken zoals Fortis. Wat wordt er eigenlijk met dat geld gedaan? E zegt: Dat geld hebben ze nodig om aan hun verplichtingen te kunnen voldoen. Een bank heeft een bepaald eigen vermogen (onder andere van jouw spaargeld) en daarmee gaan ze beleggen. Als die beleggingen ineens verlies maken, hebben ze meer eigen vermogen nodig om die verliezen mee te kunnen betalen. Maar dat geld hebben ze nu niet. Om te voorkomen dat die banken hun deuren moeten sluiten en al die beleggingen in rook opgaan, stoppen overheden geld in banken zodat ze hun verplichtingen weer na kunnen komen. A zegt: Kan de crisis ons, gewone mensen met gewone huizen en gewone inkomens, wél raken op korte termijn? E zegt: Eigenlijk niet, volgens mij. Sommige mensen zeggen dat de huizenprijzen binnenkort ook in Nederland gaan dalen. Dat kan vervelend zijn voor mensen die hadden gerekend op een hoge opbrengst, of voor mensen die hun huis als een soort van pensioen zagen. Er kan een punt komen dat je huis minder waard wordt dan de hypotheek die je hebt afgesloten. Dat zal de bank niet leuk vinden, want die loopt dan een groter risico als jij je hypotheek niet meer kunt betalen (het onderpand is minder waard dan de schuld, dat is er in Amerika nu aan de hand). En wat ik eerder zei: omdat banken zo bang zijn om geld uit te lenen aan elkaar of aan andere bedrijven, kunnen die bedrijven ook minder investeren. Dat gaan we ook merken, de groei in Nederland zal afremmen, de werkloosheid gaat oplopen. Maar of we in een recessie terecht komen, ik durf het niet te zeggen. En wat jij en ik ervan gaan merken, ook geen idee. Dat is het rare van deze crisis: het blijft een soort ver-van-mijn-bedcrisis. Maar zeg eens eerlijk, dat was de internetcrisis toch ook? A zegt: Oké Egbert. Laatste vraag. Ik vind je redelijk ontspannen in de hele crisis staan. Maken we ons dan allemaal om niks zorgen? E zegt: Heel eerlijk gezegd maak ik me persoonlijk weinig zorgen, maar kijk om je heen en je ziet wel een heleboel 'schokkende' dingen gebeuren. Al die banken die in de problemen raken, betekent natuurlijk wel iets. Al was het maar omdat ze geen geld meer kunnen uitlenen en dat de groei afremt. En al die pensioenfondsen die hun geld hebben belegd en nu dat kapitaal in waarde zien dalen. Maar één ding weten we allemaal zeker: over een tijdje gaat de beurs weer omhoog, en dan is iedereen deze crisis weer vergeten. Tot de volgende crisis natuurlijk. |
Hieronder het chatgesprek tussen Walter Moerkerken en Corjanne Lucassen, Accountmanager Levensverzekeringen en Vermogensbeheer bij Allianz Nederland.
C: Corjanne Lucassen
W: Walter Moerkerken
| Chatgesprek2 |
|---|
|
W zegt: W zegt: Hoi Corjanne, ben je klaar voor het interview? C zegt: Ja, helemaal. W zegt: Ok, dan kom ik met mijn eerste vraag. Kan je me kort uitleggen wat de kredietcrisis precies is? C zegt: Volgens mij is de kredietcrisis begonnen in Amerika. Daar is het consumentenvertrouwen in de financiële wereld en het vertrouwen van banken en financiële instellingen in elkaar langzaam weggeëbd. W zegt: En als het vertrouwen in elkaar wegebt, hoe is dat dan een oorzaak van de crisis? Wat gebeurt er dan precies? C zegt: Dan gaan de consumenten minder besteden en zijn ze bang om grote aankopen te doen, zoals een huis. Doordat de banken elkaar niet meer vertrouwen, willen ze geen geld meer aan elkaar lenen en wordt het financiële systeem star en strak, wat ertoe leidt, dat als er een kleine schommeling is, er meteen problemen zijn. En problemen leiden tot een crisis W zegt: Ik ben een leek hoor, maar een kleine schommeling waarin precies, bedoel je? C zegt: Een kleine schommeling in aandelen. Een bank krijgt het opeens zwaar, doordat de beleggingen iets minder gaan. In een gezonde financiële wereld zou ze dan zonder problemen geld kunnen lenen om deze tijdelijke situatie even op te lossen, maar in tijden van crisis wordt er niet meer geleend. Begrijp je het nu? Een bank kan dan zomaar failliet gaan, terwijl er niet zoveel aan de hand is. W zegt: Dus als ik het goed begrijp begint een crisis bij de banken. Pas als de consumenten hier lucht van krijgen en angst krijgen ontstaan de echte problemen? Klopt dit? C zegt: Tegelijkertijd is het een samenspel tussen de banken en de consumenten. Doordat de consumenten angstig worden gaan ze minder kopen, de beleggingen gaan naar beneden, crisis bij de banken, de banken lenen niets meer uit. Ook bijvoorbeeld hypotheekverstrekkingen worden moeilijker, waardoor consumenten nog minder gaan besteden. W zegt: Ok, dat begint duidelijk te worden. Maar nu eigenlijk de centrale vraag: Moet ik me, als student met een beetje spaargeld, zorgen gaan maken? C zegt: Nee helemaal niet, je spaargeld staat veilig in Nederland. En verder moet je je er weinig van aantrekken, lekker verder leven. W zegt: Ik hoef me ook geen zorgen te maken dat ik op een dag niet meer kan pinnen, en uit de prullenbak moet gaan eten? C zegt: Nee helemaal niet. De regering heeft goede plannen voor een dergelijke crisis en zal dat waar jij bang voor bent nooit laten gebeuren. W zegt: Ja, de regering lijkt als het nodig is in te springen. Maar is het wel eerlijk voor andere banken dat de regering bijvoorbeeld Fortis ineens lijkt te helpen? C zegt: Dat kan je je afvragen. Ik vind het op zich niet verkeerd dat ze helpen. Als ze dat niet zouden doen, zouden wij hier een flinke crisis krijgen. Maar ik vind het niet eerlijk dat Fortis nu reclame gaat maken dat als je daar je geld wegzet, het erg veilig staat, omdat ze nu deel van de staat zijn. Dat terwijl de banken/verzekeraars die het op eigen kracht doen eigenlijk veel gezonder zijn, financieel gezien W zegt: Maar die hebben er waarschijnlijk ook weer baat bij, dat de regering het land uit de crisis probeert te halen? C zegt: Ja dat is waar, maar het moet niet tot oneerlijke concurrentie gaan leiden en dat gebeurt nu soms wel. W zegt: Ik snap wat je bedoeld. Iets wat ik ook lastig vind is om in deze tijd de waarde van geld in te schatten. Ik hoorde een econoom zeggen dat het misschien slim is wat staafjes goud aan te schaffen. Zit hier iets in? Of moet ik geld gewoon in een sok gaan bewaren? C zegt: Goud is iets wat over het algemeen zijn waarde behoudt. Geld in een sok is echter zeer onverstandig. W zegt: Ok, dan ga ik dat maar overwegen. Kan ik uit dit interview concluderen dat de man van de straat eigenlijk zich zorgen maakt om niets? C zegt: Juist. Gewoon lekker blijven consumeren! Wanneer je gewoon je normale leefpatroon aan blijft houden, help je jezelf en je landgenoten het meest. W zegt: Ok, angst is dus ook in deze een slechte raadgever.... C zegt: Ja dat klopt, dat zie je goed. W zegt: Dankjewel voor deze korte bijspijkercursus! C zegt: Graag gedaan! |
Hieronder het chatgesprek tussen Roland Swinkels en Dick van Ooyen, Teamleider Rabobank Maas en Waal.
D: Dick van Ooyen
R: Roland Swinkels
| Chatgesprek3 |
|---|
|
R zegt: Hoi Dick D zegt: Hoi Roland R zegt: Nou mijn eerste vraag: wat is de kredietcrisis? D zegt: Kredietcrisis is eigenlijk een tekort aan liq.middelen op de kapitaalmarkt. Tekort wat is ontstaan door het feit dat aandelen kelderden door Amerikaanse toestanden en daardoor banken elkaar niet meer vertrouwden m.b.t het uitlenen van geld. Amerikaanse banken waren niet meer te vertrouwen omdat ze bewust (?) risico's aan andere banken hadden overgedragen. R zegt: En hoe onstaat dat vertrouwensverlies van banken onderling? D zegt: Doordat risico's door drie grote banken zijn overgedragen aan meerdere kleinere en hun weer risico's wederom hebben overgedragen aan kleinere banken, verzekeringsmaatschappijen en particuliere/zakelijke beleggers is het vertrouwen geschaad. We hebben het hier natuurlijk over miljarden US dollars. Banken en beleggers hadden aandelen in hun bezit die uiteindelijk niets waard bleken te zijn. De waarde van onderpanden (zoals huizen) verdween als sneeuw voor de zon. R zegt: Oké het is me grotendeels duidelijk, maar zoiets gebeurt toch niet van de een op de andere dag? Is dit niet van tevoren aan zien te komen? D zegt: Tja, hier gaat natuurlijk al heel lang een discussie over. Sommige zijn van mening dat banken dit hadden moeten zien aankomen terwijl banken zeggen dat ze van niets wisten. Volgens mij hebben de drie grote banken dit bewust gedaan (is later niet helemaal bewezen, maar de topmannen zijn inmiddels allemaal van het bank toneel verdwenen). D zegt: Misschien verstandig om je de bron uit te leggen? R zegt: Ja graag D zegt: Het Amerikaanse huizenwereldje is anders geregeld dan in Nederland. Hier in Nederland ligt alles vast in de WFT en door regels van DNB. Deze worden weer streng gecontroleerd en als banken zich hier niet aan houden kan hun banklicentie worden afgenomen. In Amerika is dit anders. Daar verkopen tussenpersonen op provisiebasis hypotheken. Deze personen konden vrij handelen. Nu moet je denken dat in Amerika de rente rondom de 1% lag. De stijging van het onroerend goed lag tussen de 10 en 20% op jaarbasis. Wat zeiden deze tussenpersonen. Laat de rente bij de schuld opvoeren. Immers, de waarde zou immers jaarlijks flink stijgen. Werkelozen en mensen met een uitkering konden op deze manier toch een hyptheek krijgen. De stijging stopte en schulden waren inmiddels zo hoop opgelopen dat mensen hun huis moesten verkopen. Banken hebben deze schulden in drie pakketjes gedaan. Veel, weinig en geen risico pakketjes. Deze zijn verzekerd doorverkocht aan kleinere banken. Je begrijpt dat uiteindelijk van deze pakketjes niet meer overbleef en de verzekering niet kon uitkeren (zoveel geld hadden ze natuurlijk niet) Dit bleek dus een schijnzekerheid te zijn... D zegt: Duidelijk zo? R zegt: Dat is helemaal duidelijk. Maar als ik het goed begrijp wordt er door die schijnzekerheid dus gewerkt met, als ik het zo kan formuleren, 'virtueel' geld? D zegt: Ja en nee. Het geld zat natuurlijk bij de huizenbezitters (althans in hun huis). Banken hebben toonderpapieren gebundeld en doorverkocht op de beurs. Op deze beurs kochten banken, verzekeringsmaatschappijen en beleggers deze aandelen (met geld). Dit vloeide terug naar de Amerikaanse banken... Banken, maatschappijen en sommige beleggers hadden op hun beurt weer geld geleend om deze aandelen te kunnen betalen. Immers, er zou een grote winst kunnen worden gemaakt bij verkoop. Tja, en dit laatste zorgt ervoor dat vele in de problemen zijn gekomen. R zegt: Oké, hoe de kredietcrisis tot stand is gekomen is mij tot zover duidelijk. ik ga verder met de volgende vraag. De Nederlandse overheid heeft een grote rol gespeeld om dit probleem in Nederland zover mogelijk op te lossen. Is de aankoop van Fortis bijvoorbeeld een slimme zet geweest? D zegt: Fortis had natuurlijk twee problemen. Enerzijds hadden liq. problemen ivm de aankoop van ABN AMRO. Hier bleken ze veel te veel voor betaald te hebben. Anderzijds hadden zo ook nog flink wat van die (waardeloze) aandelen in hun bezit. Andere handelsbanken waren bang dat Fortis de geleende gelden niet meer konden terugbetalen. Balanstechnische gezien kon het wel, echter ze hadden te weinig liquide middelen. Vandaar de steun van Bos. R zegt: Is deze overname van Fortis nou juist positief of negatief voor concurrerende banken? D zegt: Tja, als er geen vertrouwen is, is dat natuurlijk nooit goed. Van de andere kant zijn er veel klanten o.a. naar de Rabo overgekomen omdat ze geen vertrouwen hadden in hun eigen bank. Zeer zeker na het geval met Icesave. Dit laatste is dus positief voor oa. de Rabobank geweest. R zegt: In deze situatie heeft de overheid gegarandeert dat een hoop mensen niet voor hun spaargeld hoeven te vrezen, maar wat nou als zo'n crisis weer een keer gebeurt? Is die zekerheid er dan weer? D zegt: De overheid heeft ingespeeld op de onrust in de financiele markt. Simpel, als banken het vertrouwen in elkaar onderling verliezen dan is het logisch dat de klant zijn of haar spaargeld weghaalt bij desbetreffende bank. Dit begon al toen ABN AMRO in de verkoop ging. Grote advertenties van Bos was het gevolg. Daarin gaf hij aan dat er 'niets' aan de hand was. Echter, dit heeft niet mogen baten zoals je inmiddels weet. Fortis en ABN AMRO kwamen daardoor in de problemen. Dit werd nog eens een keer bevestigd toen Icesave failliet ging. Als reactie gaf DNB (bij monde van Bos) aan dat alle spaargeld tot een ton verzekerd was. Dit bracht uiteindelijk wel wat rust. De regering zal zeker niet twijfelen om dit nog een keer te doen bij een volgende keer. Immers, de financiele stroom moet op gang blijven. Lees naast financiele stroom ook de economie. Toch blijft de consument zijn gedrag aanpassen. Angst voor de toekomst zorgt er voor dat de consument wacht met uitgeven. Dat zie je nu al aan de huizen- en autoverkoop. Als gevolg hiervan zijn banken ook voorzichter met het verstrekken van financieringen. Enerzijds omdat DNB de regels van liquiditiet voor banken heeft aangescherpt, anderzijds de voorzichtigheid met financieren aan branches waar al problemen mee zijn bv. de autoindustrie. R zegt: Ik snap het, maar is deze angst van consumenten legitiem? Moet ik mij als student bijvoorbeeld zorgen maken? D zegt: De angst is niet helemaal legitiem. Het is ingewikkeld, maar o.a. de media zorgen er mede voor dat de tendens negatief is. Immers, als iedereen blijft lezen dat het slecht gaat gaat de consument meer sparen voor z.g.n. slechtere tijden. De rol en de invloed van de media hierin is overigens een gewild studieobject. De consument geeft op dit moment geen geld uit voor grotere aankopen terwijl het geld er wel is. Je ziet ook dat de consument niet bespaard op bv sinterklaas- en kerstinkopen. Als ze echt geen geld hadden gehad, dan hadden ze dit zeer zeker ook niet gedaan. Jij als student hoeft je voorlopig nog geen zorgen te maken, echter.. als de situatie niet verbeterd zal op korte termijn de werkeloosheid snel stijgen en hier kun jij weer de dupe van worden als je later een baan zoekt of nu een vakantiebaantje heeft. Je ziet nu al bv bij Rabo Druten dat het budget voor hulp- en vervangingskosten met enkele tonnen is gedaald. Ook het budget van marketing wordt flink naar beneden bijgesteld. Dit heeft zeker invloed, dat kun je begrijpen. R zegt: Aha, ik moet er dus wel rekening mee houden dat het mij kan tegenwerken. Maar als ik je antwoord kort samenvat maken we ons over het algemeen druk om niets. D zegt: Voor de korte termijn en voor de gemiddelde particulier geldt dit inderdaad. Maar... als dit langer zo blijft dan zullen de productiekosten van goederen en diensten stijgen. Dit zie je als consument terug in de prijzen bij bv de supermarkt. Ook de huizenverkoop zal teruglopen of zelfs in elkaar zakken, met alle gevolgen van dien. Het is zo, als de vraag naar een product hoog is, gaat de prijs stijgen. Dit zie je nu ook op de kapitaalmarkt... De vraag naar liq.middelen is hoog, dus de rente gaat ook die kant op. Nu wordt er door de regering, IMF en DNB ingegrepen door renteverlagingen te bieden. Zag je voorheen dat als de rente bv met 0,25 was gedaald, dit een positief effect had. Dit is inmiddels grotendeels niet meer van toepassing. Er zijn dan ook grotere rentedalingen geweest en deze hadden minimaal effect. Na de laatste rentedaling deze week is deze tendens gekeerd. R zegt: Helder, ik denk dat ik een redelijk beeld heb van de huidige kredietcrisis. R zegt: daarnaast ben ik ook door mijn vragen heen :-) |