Onderzoeksmethoden 2/het werk/2010-11/Groep01
Group Members
Inhoud
Introduction
Social media is an upcoming trend and is moving towards a hype. The media attention is very high for these social media. More and more people are using social media. Twitter is a great example for social media. The term that is used for placing messages on twiter is called microblog. Twitter is a medium where anyone in the world (who has internet or a mobile phone) can post small text messages. The power of twitter is that everyone with an account can place of short message on the website of twitter without any censorship. No proffesional editors are involved. A lot of political leaders post messages on twitter even during debates and meetings.
Problem statement
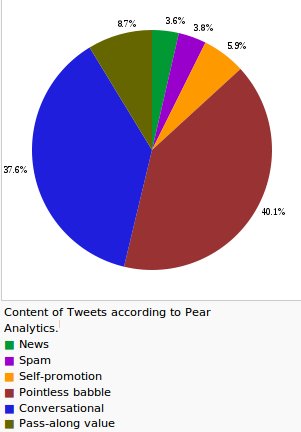
Eveyone can post messages on social media, are these messages reliable? San Antonio-based market research firm Pear Analytics Analyzed 2000 tweets (originating from the U.S. and in English) on a two-week period in August 2009 from 11:00 a to 5:00 p (CST) and separated themself writing six categories: As you can see in the diagram at the right, the research shows that 3.6 percent of this is news. [1] Unfortunately there is no data of the Netherlands available, but also in the Netherlands is a clear trend of news on twitter noticeable.
But how reliable is a social medium like twitter, because anyone can put a (news)message on this and a lot of people read this messages. Hence the question
- Are newsmessages from twitter equally reliable as newsmessages from common-media?
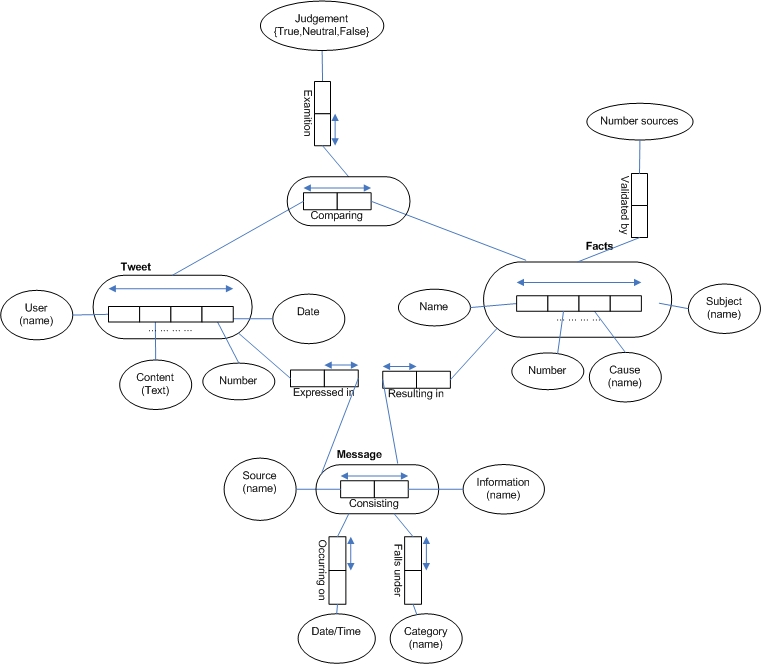
Conceptual model
Conceptual model:
| Currently Twitter is adding locations to the tweets. Could a location add more reliability to a tweet? Not every tweet has a location, so maybe it's not possible to add locations to your research.. maybe this could be part of the reflection? |  |
|
| Jodocus Deunk → Onderzoeksmethoden 2 | Remove this comment when resolved! | |
| This is not relevant for our research question and falls out of scope because we don't want to stipulate this. But maybe in the future this can be added in other question. Thxx for the comment. | |
|
| Steven de Bruijn → Onderzoeksmethoden 2 | Remove this comment when resolved! | |
Method
In this study we investigate if messages from social media are reliable. In this case we use text analysis as main method. Once the research question is known, it’s important to begin to draw up a conceptual model. This model represents a visual picture of the research-domain. So this model helps us to get a clear view of our research. Even more important, the conceptual model will be used as a base for the tagging-scheme.
Protocol & Tagging
The difficult part in this study is the interpretation by the researcher, because we are with three researchers. To make sure that we keep the difference in approach and interpretation (and thus correct tagging of messages) to a minimum, we have set up a protocol. (to be found under approach) Besides the protocol we have a tagging scheme, with relevant topics such as date, user, etc. The tags are derived from the conceptual model. Important in this tagging-scheme is that by using the selected tags, differences between the messages from social media and newspapers can be seen. With this tagging scheme we can eventually reduce the social message to be true or false. This is obviously important for the analysis.
But there is a part that provides us with a complex situation. The approach as written down below explains how dealt with the part that where subjectivity. This subjectivity made the assignment also interesting. Most of these problems are handled with our protocol that we have used but some parts can’t capture within it.
To counter this with we have used a lot of data facts that where stated in the facts of the newspapers. An example is “10 people died in the disaster of Duisberg”. To our surprise the tweets contained a lot of data facts. This made our job a lot easier because if the data that is stated in the tweet doesn’t correspond with the fact it was false of course. Also by selecting the cause and the other parts in as stated in the tagging schema made our job much easier. The tweets where just copped up in to smaller parts and could be analyzed. With this approach we could focus more on the tweets and prevent more the subjectivity. If the there are contractions within a tweets it just became neutral because it just wasn’t possible to determine the true or false category.
Data gathering
First we made the assumption that the ANP and Volkskrant are reliable. Next we have selected article that where about the disaster in Duisberg. We have selected 15 articles from the newspapers. Next we derived the facts just by reading the text and looking for the data facts. Then we have applied the tag schema and selected the cause, subject, name and time of each data fact. Some after that we a lot of data. Then we have structured the data into active form and counted the facts. So if a fact had more than one source we have selected it. The final overview was the bunch of data that is showed in the section Data -> Facts. Basically the same approach was just used by the big difference was that there are different attributes used. The section Data -> Tweets gives the overview the gathered tweets. Afterwards these facts are compared with the tweets. For any fact that we have found in the reliable media. We scaled the tweets for importance by adding a weight to a tweet. If tweet and a fact matched more than once it considered more important than 1 tweet. This gives a better impression if twitter is more reliable or not. Also we’ve chosen one subject for all messages (facts and tweets); the Duisburg love parade incident.
Data analysis
Now we have the tweets and the facts and the next step is to compare them. The bases of the tweets and the facts are the same they both have a topic. In the tagging schema they are called different. If the topic match you can determine if the compare or not. The facts from reliable newspapers are chosen that there can be minimize interpretation involved. Thus, the facts are often equipped by numbers, e.g. 10 people are died. By comparing the facts with the tweets form twitter, there will be a judgment outcome like true, neutral or false. This judgment also will be done very strictly, based on the tagging. If tagged properly the judgment is fairly easy to make. This means we have spend a lot of time of tagging the tweets and facts. We have also checked the work together.
Example
The first step is to find a fact out of newspaper. The fact below is from an article from the “Volkskrant” and the “NRC”. So first the articles that are related to the subject are scanned. Next the facts are gathered from the articles. The example in this case is:
Fact:
Doden bij Loveparade: Negentien doden en drie honderd gewonden door gedrang bij Loveparade.
The fact is tagged with a nr but more important a subject. In this case is about the death of 19 people and 300 people how are injured. Next the tweets will be selected. The twitter database is searched. Next the tweets that are interesting are selected and tagged according to the tagging schema. The most important thing is the subject and this about people that are injured and people that are hurt.
Tweet:
19 doden, 340 gewonden. Ongelooflijk... #loveparade
Next the judgment will be done. It’s about the whole tweet and the information doesn’t match so in this case that is tweet is false. There 300 people that are injured and not 340 people. Interesting to comment here is that the date of the tweet is after the date of the news article.
Judgement & Weighting:
We've matched all the facts & tweets. Thus we took a fact and took all relevant collected tweets for this particular fact. Then we judged the tweets per fact (by following our approach, described earlier). At the end we had the total number of true, false and neutral facts. After calculating we could state that tweets were reliable. (Important to note is that we left the 4 neutral tweets out of the calculation)
To improve the conclusion we've added weighting by counting the total number of tweets found per fact. More tweets per facts is better than just one. If the difference in tweet numbers is very large the conclusion with the old calculation would not be very precise. We wanted to take this difference in tweet-amounts into account, so we balanced all totals with this counting, resulting in a more precise outcome.
Take for instance the following weighting example:
The largest tweet number found (in the collection) for a fact is 8.
A Fact, 7 tweets found, 6 of those are false & 1 are true
Unweighted rating:
6 True
1 False
Weighted rating:
(7/8)*6 = 5,25 True
(7/8)*1 = 0,875 False
As you can see in this case the largest number of tweets founds per fact (in this case 8) is calculated in the weighting to lower the score if less tweets are found. So the difference in number of tweets found per fact, is now taken into account
Of course this example is very simple. If you take the totals of more facts (true, false, total numer), which you than sum up, then you get al real rating. (see excel sheet below for our results)
Conclusion
To be able the answer the research question, we are going to draw a conclusion based on our findings. In the previous section we have made overview which indicates which tweets and facts matched and what the judgment is. Therefore we can count the number of twitter messages that are correct in correspondence with the reliable news messages. With this information we can draw a conclusion by dividing the true tweets by the all the tweets. The outcome indicates if the media is reliable of not. We have made a scale to interrupt the value.
- If the total rating is between 0% and 40% we can say that isn't very reliable
- If it is between 40% and 60% we can state that it is quite reliable;
- If it is above 60% and between 100% we can state that it is very reliable. Then it will mean that social media are as reliable as common media such as newspapers.
Approach
Protocol:
Select a recent newsmessage from a objective source like "ANP" or the "Volkskrant". From these source we select the facts that are stated in the newsmessages. This means that we have a bundle of the facts from different sources. Next we made a ordend list of those facts and also added the times the facts is stated in the sources. This helps to create a more objective overview of the facts. It's important to keep in mind that time plays a big role in this story too. Some facts can alter in the course of time, that is why we have select a fact on a given time. We some statement from different sources are conflicting we have excluded them from the list.
With recent we mean that the message must be within reasonable. period of the occures. Next select the social media message(Twitter) by searching on the topic (or topics) from the newsmessage. The goal is to select five twitter messages that relate to the statements from the obective sources. Important is that it is about the same topic, and there are facts mentioned in this message. If there a less that is not a problem because the numbers of statements from twitter will be normalizated.
It's also important that you copy the original message. So no data should be changed. Then take the code scheme, which is your basis. Identify the action and subject, and if availible the cause. Then judge the sociale message by comparing it to the orginal message. If the facts (not the opion which is given within the tweet!) are the same: the judgement is true, else if there aren't the same: the judgement is false. If you can't compare it, or there is a true and false fact mentioned in the tweet, then the jugdement is neutral. Only the message for the users will be select so not the message from news sources. And if a message is referring to a newsarticle it is also not selected because it has to do for messages itself.
Planning
The time availible for this research is 11 weeks. The following global planning will be followed:
| Activity | Planned Time | Invested Time | Completed? |
|---|---|---|---|
| *Voorbereiding | 10 Hours | 8 Hours | V |
| *Data-verzameling | 30 Hours | 22 Hours | V |
| *Data-verwerking | 20 Hours | 5 Hours | V |
| *Analyse | 15 Hours | 8 Hours | V |
| *Rapportage | 15 Hours | 4 Hours | 1/2 |
Data structurering
Tagging-scheme:
<tweet> <nr></nr> Unique number of the tweet <user></user> Username of the tweet <date></date> Posting date of the tweet <cont></cont> Text in the tweet </tweet> <fact> <nr></nr> Unique number of the fact <stat></stat> Statement text that is seen as a fact <date></date> Date of the fact <nrsource></nrsource> The number of sources that have the same statement <cause></cause> The cause of the fact </fact> <matching> <tweetnr></tweetnr> Unique number of a tweet <factnr></factnr> Unique number of a fact <judge></judge> The judgement of the similarity (True, Neutral, False) </matching
Data analysis
Variables
The following variables will be used to determine the total score.
- Tweet = If the tweet is true this indicated with a 1 and if it is false is indicated with an 0.
- Fact = The total number of facts and it is just a number.
- Totale score = Overall score to draw a conclusion and it is number that is expressed in a precentage.
To determine if the tweets are reliable we have to calculate the total score. This will be done mathematically with the help of the formula below. The result of this formula will provide us with a number which will indicate whether the tweets are reliable or not :
- Parsen mislukt (MathML met SVG- of PNG-terugval (aanbevolen voor moderne browsers en toegankelijkheidshulpmiddelen): Ongeldig antwoord ("Math extension cannot connect to Restbase.") van server "https://en.wikipedia.org/api/rest_v1/":): {\displaystyle {Total score}=\frac{True tweets}{All tweets}\times 100 %}
Scale:
To determine whether the total score is significant for our research question we have to determine a scale. There no scale used in a researched for this kind of research. That is why we have selected our own scale. Based on this scale we can draw our conclusion and answer the research question:
- If the total rating is between 0% and 40%, we can say that it isn't very reliable because the score is too low.
- If it's between 40% and 60%, we can state that it is quite reliable because not too low or high.
- If it's above 60% and between 100%, we can state that it is indeed very reliable. Then it will mean that social media are as reliable as common media such news papers.
Data
Facts:
- <nr>1</nr><stat>220 aangiftes gedaan tegen de organisatoren, de stad Duisburg en de politie</stat><date>11 aug</date><nrsource>1</nrsource><cause>Aangiftes</cause>
- <nr>2</nr> <stat>21 mensen zijn overleden</stat> <date>5 aug</date> <nrsource>6</nrsource> <cause>Doden</cause>
- <nr>3</nr> <stat>Politie heeft 80 man op de zaak gezet</stat> <date>11 aug</date> <nrsource>1</nrsource> <cause>Politiemannen</cause>
- <nr>4</nr> <stat>De onderzoekers moeten ruim negenhonderd uur beeldmateriaal van bewakingscamera's, foto- en video-opnamen van de politie, telefoonvideo's van bezoekers</stat> <date>11 aug</date> <nrsource>1</nrsource> <cause>Bewijsmateriaal</cause>
- <nr>5</nr> <stat>Burgemeester Sauerland van Duisberg mag blijven.</stat> <date>6 aug</date> <nrsource>3</nrsource> <cause>Burgemeester</cause>
- <nr>6</nr> <stat>50 mensen(tweederde) zijn stemmen waarvan minimaal een van de CDU om burgemeester te ontslaan uit zijn functie.</stat> <date>6 aug</date> <nrsource>3</nrsource> <cause>Motie wantrouwen Burgermeester</cause>
- <nr>7</nr> <stat>Bezoekersaantal loveparade gemanipuleerd</stat> <date>31 juli</date> <nrsource>3</nrsource> <cause>Bezoekersaantal</cause>
- <nr>8</nr> <stat>Bezoekersaantal Essen was 1,2 miljoen</stat> <date>31 juli</date> <nrsource>2</nrsource> <cause>Bezoekersaantal</cause>
- <nr>9</nr> <stat>Bezoekersaantal Dortmund was 1,6 miljoen</stat> <date>31 juli</date> <nrsource>2</nrsource> <cause>Bezoekersaantal</cause>
- <nr>10</nr> <stat>De linkspartij van de gemeenteraad van Duisberg heeft een motie van wantrouwen in gediend.</stat> <date>31 juli</date> <nrsource>2</nrsource> <cause>Motie wantrouwen Burgermeester</cause>
- <nr>11</nr> <stat>Burgemeester Sauerland komt niet naar de rouwdienst</stat> <date>31 juli</date> <nrsource>1</nrsource> <cause>Burgemeester</cause>
- <nr>12</nr> <stat>De verantwoordelijkheid van het festival Loveparade ligt geheel bij de organisatie.</stat> <date>29 Juli</date> <nrsource>4</nrsource> <cause>Verantwoordelijkheid</cause>
- <nr>13</nr> <stat>Er zijn onvoldoende mensen ingezet om de orde te handhaven tijdens het festival.</stat> <date>29 Juli</date> <nrsource>1</nrsource> <cause>Onvoldoende orderhandhaving</cause>
- <nr>14</nr> <stat>De capaciteit van de tunnel was 30.000 wat onvoldoende was om het mensen aantal te verwerken.</stat> <date>29 juli</date> <nrsource>1</nrsource> <cause>Tunnel</cause>
- <nr>15</nr> <stat>Een 25 jarige vrouw uit Heiligenhaus is overleden aan haar verwondingen.</stat> <date>29 juli</date> <nrsource>1</nrsource> <cause>Doden</cause>
- <nr>16</nr> <stat>Een 22 jarige Nederland tijdens de Loveparade overleden.</stat> <date>25 juli</date> <nrsource>2</nrsource> <cause>Doden</cause>
- <nr>17</nr> <stat>Vooraf gaand aan de loveparade was gewaarschuwd dat de veiligheid niet gewaarborgd kon worden door hulpdiensten.</stat> <date>28 juli</date> <nrsource>1</nrsource> <cause>Veiligheid</cause>
- <nr>18</nr> <stat>Er zijn 340 gewond geraakt tijdens de loveparade.</stat> <date>25 juli</date> <nrsource>4</nrsource> <cause>Overwonden</cause>
- <nr>19</nr> <stat>Agenten kijken naar de ramp maar handelen niet.</stat> <date>25 juli</date> <nrsource>1</nrsource> <cause>Agenten</cause>
- <nr>20</nr> <stat>Burgemeester Sauerland zetten pas om 9uur ’ s ochtends zijn handtekening onder vergunning.</stat> <date>28 juli</date> <nrsource>1</nrsource> <cause>Vergunning</cause>
- <nr>21</nr> <stat>Te veel ruimten tussen de groepen mensen volgens de politie</stat> <date>28 juli</date> <nrsource>1</nrsource> <cause>Bezoekers</cause>
- <nr>22</nr> <stat>16 toegangspoortjes waren beschikbaar waarvan 6 niet open waren. De poortjes gingen daarna wel open.</stat> <date>28 juli</date> <nrsource>1</nrsource> <cause>Poortjes</cause>
- <nr>23</nr> <stat>Paniek ontstond in de tunnel toen de politie de ene kant afsloot waardoor mensen gingen duwen om naar binnen te komen.</stat> <date>28 juli</date> <nrsource>1</nrsource> <cause>Paniek</cause>
- <nr>24</nr> <stat>Mensen proberen gebruik te maken van de noodtrap en mensen vielen ervan af in de mensen massa.</stat> <date>28 juli</date> <nrsource>1</nrsource> <cause>Noodtrap</cause>
- <nr>25</nr> <stat>De organisator ontkent alle schuld omdat alle vergunningen waren ondertekend.</stat> <date>28 juli</date> <nrsource>2</nrsource> <cause>Vergunning</cause>
- <nr>26</nr> <stat>Burgemeester wist niet dat de hulpdiensten bezwaren had.</stat> <date>28 juli</date> <nrsource>1</nrsource> <cause>Ordehulpdiensten</cause>
- <nr>27</nr> <stat>Het feest ging gewoon door om nog meer paniek te voorkomen.</stat> <date>26 juli</date> <nrsource>1</nrsource> <cause>Paniek</cause>
- <nr>28</nr> <stat>Het festival is 250.000 meter groot.</stat> <date>26 juli</date> <nrsource>1</nrsource> <cause>Grootte terein</cause>
- <nr>29</nr> <stat>De burgemeester is bekogeld met vuil door buurtbewoners</stat> <date>26 juli</date> <nrsource>3</nrsource> <cause>Burgemeester</cause>
- <nr>30</nr> <stat>De rouwdienst werd gehouden in de kerk van Duisburg met 550 zitplaatsen en op grote schermen in het station van MSV Duisburg.</stat> <date>31 juli</date> <nrsource>1</nrsource> <cause>Rouwdienst</cause>
Tweets:
- <nr>1</nr><user>wikileaks/user><date>Jul 24, 2010</date><cpnt>Loveparade, 24. July 2010 Duisburg (DE), 21 dead, 511 wounded. Profits and cover-ups are more valuable than human life. http://bit.ly/cIW1oZ<cont>
- <nr>2</nr><user>Noticias24</user><date>Jul 24, 2010</date><cont>noticias24.com/ “Mueren 10 personas durante un tumulto en el Festival Tecno de Duisburg (Alemania) - http://bit.ly/16reFK ”<.cont>
- <nr>3</nr><user>n24_de</user><date>Jul 24, 2010</user><cont>Eil! +++ 10 Tote auf der #Loveparade in Duisburg +++ Gleich mehr auf www.n24.de</cont>
- <nr>4</nr><user>breakingnews</user><date>Jul 24, 2010</date><cont>German police: 10 killed, 15 others injured in mass panic at Love Parade techno music festival in Duisburg - AP http://bit.ly/bdnJzt</cont>
- <nr>5</nr><user>chijs<user><date>Jul 24, 2010</date><cont>News about #loveparade #duisburg seems to be true. German TV stops live coverage, mass panic, 10 death, 100 wounded.</cont>
- <nr>6</nr><user>derwesten</user><date>Jul 24, 2010</date><cont>Zehn Tote bei der Loveparade in Duisburg, sagt die Polizei. 100 Verletzte einige werden noch reanimiert.</cont>
- <nr>7</nr><user>boysnoize</user><date>Jul 24, 2010</date><cont>..cause 15 people died and about 50-100 got hurt. knowing this i just cant go up there and play for the rest 500 000 people #loveparade</cont>
- <nr>8</nr><user>steveaoki</user><date>Jul 24, 2010</date><cont>Rip to 15 people who died at loveparade fest.</cont>
- <nr>9</nr><user>radiofreestyle</user><date>Jul 25, 2010</date><cont>19 dead over 300 injured in Love Parade disaster | DanceNova dancenova.com/news/19-dead-over-300-injured-in-love-parade-disaster/12476.html “[DanceNova] 19 dead over 300 injured in Love Parade disaster: 1.4 million young people from all over Europe packed..</cont>
- <nr>10</nr><user>@order_by_rand</user><date>Aug 21 2010</date><content>Kaum ist das Thema #loveparade 4 Wochen in den Medien, schon fängt die Polizei an Beweise zu sammeln. http://goo.gl/fb/TVVfq #zdf #schaller</content>
- <nr>11</nr><user>firmadankt</user><date>Jul 26, 2010</date><content>Dutzende #Amateurvideos zeigen Massenpanik http://j.mp/cQPX6l #Loveparade - Alles Beweise!</content>
- <nr>12</nr><user>ciffi</user><date>Sept 14, 2010</date><content>wer (doofes) buch schreibt, fliegt raus (sarrazin); wer (tödliche) loveparade veranstaltet (sauerland), bleibt drin. eindeutig #kulturnation</content>
- <nr>13</nr><user>webrebell</user><date>5 okt 2010</date><content>Soll der rabiate Polizeieinsatz und die Fehlpolitik in Stuttgart #S21 von Adolf #Sauerland und der #Loveparade in #Duisburg ablenken?</content>
- <nr>14</nr><user>eurosavant</user><date>13 okt 2010</date><content>RT @Deutschland_ Recall attmpt fails 4 #Duisburg mayor #Sauerland (in chrge 4 #LoveParade ctstrphe), saved by CDU votes http://bit.ly/c79Rpb</content>
- <nr>15</nr><user>rtlnieuwsnl</user><date>Jul 26, 2010</date><content>'Te veel bezoekers op Loveparade': De organisatie van de Loveparade had toestemming voor 250.000 bezoekers. Het fe... http://bit.ly/9btKID</content>
- <nr>16</nr><user>nosheadlines</user><date>Jul 25, 2010</date><content>Doden bij Loveparade: Negentien doden en honderden gewonden door gedrang bij Loveparade, veel meer bezoekers dan v... http://bit.ly/c8Vjy3</content>
- <nr>17</nr><user>lammert</user><date>Jul 31, 2010</date><content>Wrang; voor de herdenking van de loveparade heeft gemeente op teveel bezoekers gerekend, voor de loveparade zelf op te weinig. #leegstadion</content>
- <nr>18</nr><user>baspaternotte</user><date>Jul 24, 2010</date><content>Ruimte voor 500.000 bezoekers, 1,4 milj. aanwezigen. Iemand is binnenkort z'n baan kwijt. #loveparade</content>
- <nr>19</nr><user>hanniepannie84</user><date>Jul 24, 2010</date><content>damn.. plaats voor 4-500.000 bezoekers. 1.4 mljn aanwezig. waarvan de helft door http://img97.imageshack.us/i/x2210a529.jpg/ #loveparade</content>
- <nr>20</nr><user>derwesten</user><date>Jul 29, 2010</date><content>derwesten: Die Teilnehmerzahlen zur #Loveparade waren in Essen, Dortmund und Duisburg gefälscht. http://www.derwesten.de/3317706</content>
- <nr>21</nr><user>derwesten</user><date>Jul 29, 2010</date><content>derwesten: Die Teilnehmerzahlen zur #Loveparade waren in Essen, Dortmund und Duisburg gefälscht. http://www.derwesten.de/3317706</content>
- <nr>22</nr><user>andreashelsper</user><date>Jul 29, 2010</date><content>Wenn Teilnehmerzahlen der #Loveparade in Essen & Dortmund falsch waren (@DerWesten), dann hat Verwaltung in Duisburg den Stadtrat belogen!</content>
- <nr>23</nr><user>haroldrolloos<user><date>Sep 13, 2010</date><cont>Mayor Sauerland of #Duisburg don't not have to resign after the #loveparade disaster. A motion of no confidence gained no majority.</cont>
- <nr>24</nr><user>parade2472010</user><date>Aug 4, 2010</date><cont>#sauerland #schaller #ob #bürgermeister #duisburg #ruhr2010 #love #parade</cont>
- <nr>25</nr><user>spiegeltv</user><date>Jul 30, 2010</date><cont>Duisburg vor der Trauerfeier: Druck auf Bürgermeister steigt http://bit.ly/9cwUlI</cont>
- <nr>26</nr><user>partyscenenl</user><date>Sep 16, 2010</date><cont>Nu online: Duidelijkheid Love Parade: De organisatie probeert met een korte documentaire meer duidelijkheid te gev... http://bit.ly/dp2loA</cont>
- <nr>27</nr>haroldrolloos</nr><date>Jul 25, 2010</date><cont>Founder of Love Parade, DJ Dr. Motte, said: 'It's a fault of the organisation. Big scandal and all about the money.' #loveparade #Duisburg</cont>
- <nr>28</nr><user>mjcat63</user><date>Jul 26, 2010</date><cont>I m so sad ! 19 young people died at LOVE PARADE Germany mass panic more than 300 were died my opinion is organisation do anything 4 money !</cont>
- <nr>29</nr><user>heerenleed</user><date>Jul 25, 2010</date><cont>now 19 dead in Love Parade.Officials blame organisation who was only prepared for 500.000 people instead of the 1.000.000 who actually came</cont>
- <nr>30</nr><user>russmonk</user><date>Jul 27, 2010</date><cont>The love parade disaster looks to be as much crime as tragedy. Total lack of judgment and responsibility from the organizers. Very sad.</cont>
- <nr>31</nr><user>latexalexx</user><date>Jul 31, 2010</date><cont>Love Parade Organizers have again lowered the official number of guests: First 1.4 Million, then 1.1 M, 1 M, 750K, 550K, 250K, now 150K...</cont>
- <nr>32</nr><user>roxettemabellon</user><date>Jul 26, 2010</date><cont>DanceValley organization: "We have 4 x 25m gates for 60000 people. How can you have 1x20m gate for 1,000,000 visitors" #loveparade #duisburg</cont>
- <nr>33</nr><user>globenaut</user><date>Jul 25, 2010</date><cont>Merkwürdige Zahlen: Tunnelkapazität: 20.000 Pers./h; Dortmund: 1,6 Mio Besucher; je 80 h (=3,3 d) nur für Einlass & Abfluss #Loveparade #WTF</cont>
- <nr>34</nr><user>mxyed</user><date>Jul 24, 2010</date><cont>@iNerd_x3 : 15 people got crushed in a tunnel, 100 injured. Love Parade 1.4 miliion visitors, 'only' 300.000 expected.</cont>
- <nr>35</nr><user>rponline</user><date>Jul 28, 2010</date><cont>21. Todesopfer nach der Loveparade-Tragödie: 25-Jährige Frau aus Heiligenhaus erliegt ihren Verletzungen. http://bit.ly/cEKPMY</cont>
- <nr>36</nr><user>firefox05c</user><date>Jul 28, 2010</date><cont>@lelei33 Die Frau aus Heiligenhaus soll aber in Essen gestorben sein. Erzählen die TVler zumindest.</cont>
- <nr>37</nr><user>elleloh</user><date>Jul 31, 2010</date><cont>RT @SabrinaFries: die Frau aus Heiligenhaus war Mutter von einem 4 jährigen Kind #loveparade, ich weiß und sie war 25 Jahre alt, schlimm</cont>
- <nr>38</nr><user>ricocb</user><date>Jul 28, 2010</date><cont>Zahl der Toten auf #Loveparade #Duisburg erhöht sich auf 21! 25 Jahre alte Frau aus Heiligenhaus bei Essen ist verstorben! :-(<cont>
- <nr>39</nr><user>globbys</user><date>Jul 28, 2010</date><cont>25-jährige Frau aus dem nordrhein-westfälischen Heiligenhaus ist das 21 Todesopfer der Loveparade</cont>
- <nr>40</nr><user>dlochtenberg</user><date>Jul 25, 2010</date><cont>Nederlander (22) omgekomen bij de Love Parade. Dodental staat nu op 19. Verschrikkelijk.</cont>
- <nr>41</nr><user>died6</user><date>Sep 11, 2010</date><cont>Want in tegenstelling tot bij de Love Parade zijn er bij #berlinfestival gewoon kaarten verkocht. Men wist precies hoeveel mensen er kwamen.</cont>
- <nr>42</nr><user>drudge_report</user><date>Jul 26, 2010</date><cont>German police say warnings not heeded on Love Parade... http://drudge.tw/d8vwf1</cont>
- <nr>43</nr><user>jackelien</user><date>Jul 25, 2010</date><cont>19 doden, 340 gewonden. Ongelooflijk... #loveparade</cont>
- <nr>44</nr><user>ssoepie</user><date>Jul 25, 2010</date><cont>#loveparade Het zwarte pieten over wiens schuld het is is begonnen . Ach ja 19 doden en meer dan 340 gewonden Wir haben das nicht gewust!!!</cont>
- <nr>45</nr><user>vivazcaroline</user><date>Jul 25, 2010</date><cont>Pffff, even timeline beetje teruggelezen, maar is onbegonnen werk. Eerst #loveparade: 19 doden, 340 gewonden...heftig....</cont>
- <nr>46</nr><user>controlgirl</user><date>Jul 25, 2010</date><cont>krijg nog steeds kippenvel bij de gedachte aan t aantal doden die nog steeds stijgen..#loveparade..19 doden al en 340 gewonden</cont>
- <nr>47</nr><user>jochemfloor</user><date>Jul 25, 2010</date><cont>Oeps. 19 doden en 340+ gewonden in Duisburg. #loveparade #griphoeveel?</cont>
- <nr>48</nr><user>erickknapen</user><date>Jul 24, 2010</date><content>“Zie ik het nu goed , de politie houd de mensen tegen in de tunnel? Domme actie - http://bit.ly/93fJOD http://bit.ly/axGmOE #loveparade ”</content>
- <nr>49</nr><user>flensburgonline</user><date>Jul 24, 2010</date><content>Polizisten im Katastrophen-Tunnel der Loveparade in Duisburg: Police officers walk past thermo blanket.</content>
- <nr>50</nr><user>manuelbalzer</user><date>Jul 24, 2010</date><content>Neather the Loveparade nor police could tell anyone how to get away from the event location panoc disorientation WHY was this event so badl.</content>
- <nr>51</nr><user>bnr</user><date>Jul 26, 2010</date><content>'Vergunning Loveparade pas op de valreep': DUISBURG (ANP) - Burgemeester Adolf Sauerland (CDU) van Duisburg heeft ... http://bit.ly/9rnGrU</content>
- <nr>52</nr><user>chris_f_bln</user><date>Jul 27, 2010</date><content>Love Parade 2010-Wie konnte man diesen Veranstaltungsort seitens des Veranstalters und der Behörden zulassen?Fazit:Kohle machen egal wie :-(</content>
- <nr>53</nr><user>kes4life</user><date>Jul 24, 2010</date><content>And the fences are down.... Love Parade is crowded and entrances are bad organized... But I see some trucks :) time to party!</content>
- <nr>54</nr><user>sascha_p</user><date>Jul 24, 2010</date><content>loveparade german police blocking an exit of the tunnel before the mass panic</content>
- <nr>55</nr><user>jankarel</user><date>Jul 25, 2010</date><cont>#loveparade Look at this! Police was blocking the end of that tunnel to the loveparade terrain ... http://ht.ly/2gdvl</cont>
- <nr>56</nr><user>djandypost</user><date>Jul 24, 2010</date><cont>the police did nothing - RIP #loveparade #trancefamily</cont>
- <nr>57</nr><user>haroldrolloos</user><date>Jul 27, 2010</date><cont>All the victims at the #loveparade were crushed. No one fell down the stairs in #Duisburg</cont>
- <nr>58</nr><user>quasimundo</user><date>Jul 26, 2010</date><cont>“Vergunning LoveParade veel te laat afgegeven, dodental inmiddels op twintig</cont>
- <nr>59</nr><user>nieuwsfreak</user><date>Jul 26, 2010</date><cont>“'Vergunning Loveparade pas op de valreep'</cont>
- <nr>60</nr><user>spd_billstedt</user><date>Sep 2, 2010</date><cont>#Polizei, #Sauerland & #Schaller wollen nicht Schuld an #Loveparade in #Duisburg sein. Und was ist wenn alle Schuld haben?</cont>
- <nr>61</nr><user>dieorganisation</user><date>Jul 26, 2010</date><cont>Loveparade: Polizei warnte - "Duisburg von schwerer Bürde befreien</cont>
- <nr>62</nr><user>sueddeutsche</user><date>Jul 28, 2010</date><cont>Duisburgs OB Adolf Sauerland war offensichtlich besser über die Sicherheitsrisiken der Loveparade informiert als er zugibt. Ein Brandbrief der Bauaufsicht hatte ihn gewarnt.<cont>
- <nr>63</nr>martinbaeumler<date>Jul 24, 2010</date><cont>Duisburgs OB #Sauerland bestreitet bereits Fehler im Sicherheitskonzept. Diese Art von Populismus ist einfach arm #loveparade 2</cont>
- <nr>64</nr><user>engola</user><date>Sep 11, 2010</date><cont>Schuldig an den Toten der Loveparade nach meinem Kenntnisstand: 1. Die Polizei 2. Behörden/Sauerland 3. Der Veranstalter / diese Reihenfolge</cont>
- <nr>65</nr><user>dradio</user><date>Aug 26, 2010</date><cont>Kultur: DJ Tom Novy will Fortsetzung der Loveparade: Seit der Katastrophe von Duisburg gilt als ausgemacht, dass e.. ”</cont>
- <nr>66</nr><user>maritadejong</user><date>Jul 24, 2010</date><cont>De muziek speelt door om massa-paniek te voorkomen. Zit WDR te kijken. Zond de love-parade live uit.</cont>
- <nr>67</nr><user>jochemfloor</user><date>Jul 25, 2010</date><cont>Tagesschau ARD meldt 19 doden, deel ongeidentificeerd. #loveparade Feest ging door tot middernacht.</cont>
- <nr>68</nr><user>frankbecker</user><date>Jul 26, 2010</date><cont>“"Katastrophe: #Loveparade-Gelände nur für 250.000 zugelassen? - Nachrichten - @DerWesten" ( http://bit.ly/cP8yTr ) - #Duisburg ”</cont>
- <nr>69</nr><user>thorbengeyer</user><date>Jul 28, 2010</date><cont>Die Polizei hat erst am Samstagmorgen auf Nachfrage die Veranstaltungsgenehmigung über 250.000 Teilnehmer erhalten. #Phoenix #Loveparade</cont>
- <nr>70</nr><user>lci</user><date>Jul 25, 2010</date><cont>Loveparade: le site autorisé pour 250 000 personnes seulement http://bit.ly/cPBo72</cont>
- <nr>71</nr><user>schlagzeilen</user><date>Jul 25, 2010</date><cont>“Bild: Loveparade-Drama - Platz nur für 250 000 Raver zugelassen</cont>
- <nr>72</nr><user>kreiszeitung</user><date>Jul 26, 2010</date><cont>“Bürgermeister Sauerland muss nach Katastrophe bei der #Loveparade vor Trauernden in Duisburg flüchten</cont>
- <nr>73</nr><user>chaossturm</user><date>Jul 27, 2010</date><cont>MACH MIT, FUER EIN SAUBERES DUISBURG. ENTSORGUNG VON MÜLL. ALSO WEG MIT SAUERBRATEN UND RABE. #Sauerland #Duisburg #Loveparade</cont>
- <nr>74</nr><user>de_volkskrant</user><date>Jul 27, 2010</date><cont>Zaterdag rouwdienst Loveparade: Duisburg - Duisburg houdt zaterdag een rouwdienst voor de twintig do...</cont>
{kind=link}
Analysis
- <tweetnr>1</tweetnr><factnr>2</factnr><judge>True</judge>
- <tweetnr>2</tweetnr><factnr>2</factnr><judge>False</judge>
- <tweetnr>3</tweetnr><factnr>2</factnr><judge>False</judge>
- <tweetnr>4</tweetnr><factnr>2</factnr><judge>False</judge>
- <tweetnr>5</tweetnr><factnr>2</factnr><judge>False</judge>
- <tweetnr>6</tweetnr><factnr>2</factnr><judge>False</judge>
- <tweetnr>7</tweetnr><factnr>2</factnr><judge>False</judge>
- <tweetnr>8</tweetnr><factnr>2</factnr><judge>False</judge>
- <tweetnr>9</tweetnr><factnr>2</factnr><judge>False</judge>
- <tweetnr>10</tweetnr><factnr>3</factnr><judge>False</judge>
- <tweetnr>11</tweetnr><factnr>4</factnr><judge>True</judge>
- <tweetnr>12</tweetnr><factnr>4</factnr><judge>True</judge>
- <tweetnr>13</tweetnr><factnr>5</factnr><judge>True</judge>
- <tweetnr>14</tweetnr><factnr>5</factnr><judge>True</judge>
- <tweetnr>15</tweetnr><factnr>6</factnr><judge>True</judge>
- <tweetnr>16</tweetnr><factnr>7</factnr><judge>True</judge>
- <tweetnr>17</tweetnr><factnr>7</factnr><judge>True</judge>
- <tweetnr>18</tweetnr><factnr>7</factnr><judge>True</judge>
- <tweetnr>19</tweetnr><factnr>7</factnr><judge>True</judge>
- <tweetnr>20</tweetnr><factnr>7</factnr><judge>True</judge>
- <tweetnr>21</tweetnr><factnr>8</factnr><judge>True</judge>
- <tweetnr>22</tweetnr><factnr>9</factnr><judge>True</judge>
- <tweetnr>23</tweetnr><factnr>9</factnr><judge>True</judge>
- <tweetnr>24</tweetnr><factnr>10</factnr><judge>False</judge>
- <tweetnr>25</tweetnr><factnr>11</factnr><judge>True</judge>
- <tweetnr>26</tweetnr><factnr>11</factnr><judge>False</judge>
- <tweetnr>27</tweetnr><factnr>12</factnr><judge>True</judge>
- <tweetnr>28</tweetnr><factnr>12</factnr><judge>True</judge>
- <tweetnr>29</tweetnr><factnr>12</factnr><judge>True</judge>
- <tweetnr>30</tweetnr><factnr>12</factnr><judge>True</judge>
- <tweetnr>31</tweetnr><factnr>12</factnr><judge>True</judge>
- <tweetnr>32</tweetnr><factnr>13</factnr><judge>True</judge>
- <tweetnr>33</tweetnr><factnr>14</factnr><judge>False</judge>
- <tweetnr>34</tweetnr><factnr>14</factnr><judge>False</judge>
- <tweetnr>35</tweetnr><factnr>14</factnr><judge>True</judge>
- <tweetnr>36</tweetnr><factnr>15</factnr><judge>Neutral</judge>
- <tweetnr>37</tweetnr><factnr>15</factnr><judge>True</judge>
- <tweetnr>38</tweetnr><factnr>15</factnr><judge>Neutral</judge>
- <tweetnr>39</tweetnr><factnr>15</factnr><judge>True</judge>
- <tweetnr>40</tweetnr><factnr>15</factnr><judge>True</judge>
- <tweetnr>41</tweetnr><factnr>16</factnr><judge>False</judge>
- <tweetnr>42</tweetnr><factnr>17</factnr><judge>True</judge>
- <tweetnr>43</tweetnr><factnr>17</factnr><judge>True</judge>
- <tweetnr>44</tweetnr><factnr>18</factnr><judge>True</judge>
- <tweetnr>45</tweetnr><factnr>18</factnr><judge>True</judge>
- <tweetnr>46</tweetnr><factnr>18</factnr><judge>True</judge>
- <tweetnr>47</tweetnr><factnr>18</factnr><judge>True</judge>
- <tweetnr>48</tweetnr><factnr>18</factnr><judge>True</judge>
- <tweetnr>49</tweetnr><factnr>19</factnr><judge>True</judge>
- <tweetnr>50</tweetnr><factnr>19</factnr><judge>True</judge>
- <tweetnr>51</tweetnr><factnr>19</factnr><judge>True</judge>
- <tweetnr>52</tweetnr><factnr>20</factnr><judge>Neutral</judge>
- <tweetnr>53</tweetnr><factnr>20</factnr><judge>True</judge>
- <tweetnr>54</tweetnr><factnr>21</factnr><judge>True</judge>
- <tweetnr>55</tweetnr><factnr>22</factnr><judge>True</judge>
- <tweetnr>56</tweetnr><factnr>23</factnr><judge>False</judge>
- <tweetnr>57</tweetnr><factnr>23</factnr><judge>False</judge>
- <tweetnr>58</tweetnr><factnr>23</factnr><judge>True</judge>
- <tweetnr>59</tweetnr><factnr>24</factnr><judge>True</judge>
- <tweetnr>60</tweetnr><factnr>25</factnr><judge>True</judge>
- <tweetnr>61</tweetnr><factnr>25</factnr><judge>True</judge>
- <tweetnr>62</tweetnr><factnr>25</factnr><judge>True</judge>
- <tweetnr>63</tweetnr><factnr>26</factnr><judge>True</judge>
- <tweetnr>64</tweetnr><factnr>26</factnr><judge>False</judge>
- <tweetnr>65</tweetnr><factnr>26</factnr><judge>Neutral</judge>
- <tweetnr>66</tweetnr><factnr>26</factnr><judge>True</judge>
- <tweetnr>67</tweetnr><factnr>27</factnr><judge>True</judge>
- <tweetnr>68</tweetnr><factnr>27</factnr><judge>False</judge>
- <tweetnr>69</tweetnr><factnr>27</factnr><judge>False</judge>
- <tweetnr>70</tweetnr><factnr>28</factnr><judge>False</judge>
- <tweetnr>71</tweetnr><factnr>28</factnr><judge>False</judge>
- <tweetnr>72</tweetnr><factnr>28</factnr><judge>True</judge>
- <tweetnr>73</tweetnr><factnr>28</factnr><judge>True</judge>
- <tweetnr>74</tweetnr><factnr>29</factnr><judge>True</judge>
Conclusion
We’ve originally planned to use five tweets per fact. As you can see in the analysis we did not found five tweets for every fact. That’s due to the reason that a fact is a very specific. If no user from twitter has made a message that concerns this subject/fact, you cannot find anything of course. The facts that did not have any related tweet are is from the list. These would not have created any added value to our research. If the outcome of this research proves not to be significant, we will try to improve the overall analysis by weighting the number of tweets found per fact.
For further research & improving the outcome of this research we suggest the following:
In this research we have looked at tweets that say something about news-facts. It would be better to also research the other way around. Gather a set of tweets that spread news, and compare these with the actual reports that are made in the newspapers, or other common media. Important here is to make sure that the tweets are posted earlier than the messages in common media. This is to ensure that it isn’t just rumor spreading. So this is somewhat like, a pre-measure and after-measure structure.
We've analysed 74 tweets based on 30 facts. The goal was to find 5 tweets per fact. As you can see in the analysis we do not have met this goal.
The analysis shows that:
49 tweets are true
21 tweets are false
4 tweets are neutral
As you can see below we have used a formula to calculate the end-rating. We take the total number of tweets (true and false), and divide these trough the number of true tweets, which we than multiply by 100% to give a percentage of true-tweets. We have decided to leave the 4 neutral tweets out of the calculation. These tweets add nothing to the true- or false tweets. But if you also use the total with neutral tweets in the calculation, the outcome percentage is pulled down.
So this gives:
- Parsen mislukt (MathML met SVG- of PNG-terugval (aanbevolen voor moderne browsers en toegankelijkheidshulpmiddelen): Ongeldig antwoord ("Math extension cannot connect to Restbase.") van server "https://en.wikipedia.org/api/rest_v1/":): {\displaystyle {Rating}=\frac{49}{70}\times 100 %= 70{,}00\ %}
Looking at the outcome of this formula, we can state that with 70,00 %*, twitter is quite reliable. So, this would will mean that social media are almost equally reliable as common media such news papers.
"*The scale of reliability used, can be found under Data-analysis"
Weighting
We've added some weighting to the first outcome. This weighting is ment to weight the facts that have more corresponding tweets, than the facts where only one single tweet is found. The more tweets, the better you can say something about the reliability. In the image below, you can find the original calculation, and the weighted version.
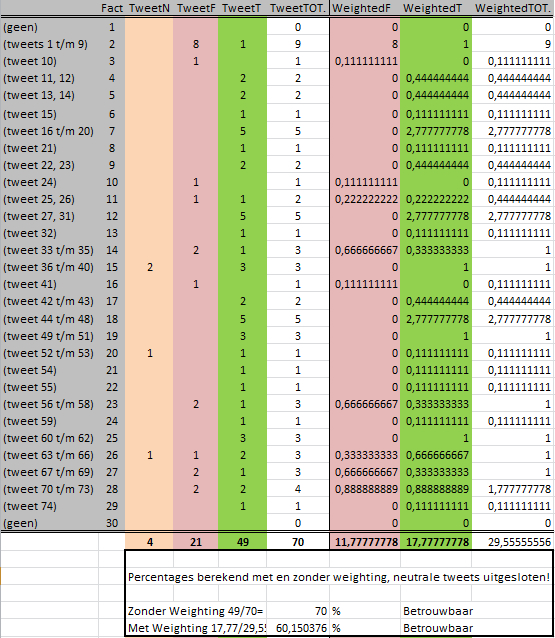
- Parsen mislukt (MathML met SVG- of PNG-terugval (aanbevolen voor moderne browsers en toegankelijkheidshulpmiddelen): Ongeldig antwoord ("Math extension cannot connect to Restbase.") van server "https://en.wikipedia.org/api/rest_v1/":): {\displaystyle {Rating}=\frac{17,78}{29,56}\times 100 %= 60{,}15\ %}
This means the outcome just falls in the reliable part of the scale ( 60% - 100%). This score is a better representation of the reliability of twitter messages.
Reflection
Conceptual
We've used ORM (object role modelling language) to set up an conceptual model. This language is ideal for setting up concepts and ideas in an structured way. We have chosen to only capture those concepts that relate to answering the research question. This conceptual model has been updated during the beginning stage of this research project. Ideas and insight grows during the project, so do the concepts. For example: concepts like location, have been left out. The concepts, entities and structure in the model are used as a base for the tagging-scheme. This ensures proper structuring in the taggin-scheme.
Method
After setting up the research question, we made a conceptual model. This was done by using an example case e.g. The election of this year. With this example case we extracted the entities we thought we needed. This manner works really well. We had almost the conceptual model as shown in chapter 3. When we checked this conceptual model by using this by another example cases, we saw a few details that we forgot, like a neutral statement (if a statement couldn't get the label true or false). After a revision was our conceptual model correct and ready to use.
The method was the most important thing in this project and we spent the most time to do the method with respect to the contents. We realized that if we spent the most time of the method part to a good tagging scheme and protocol to gathering the information, we get the most objective results and best practice.
When the method was described, we each did a sample and checked if or method was correct. We found a few things that we forgot in the tagging scheme. Particularly we changed the tagnames, because some tagnames in the tagging scheme were a little bit vague and interpretation sensitive. After this sample we started with the real case, so we didn't test our information analyse and conclusion with this sample.
After doing this, we started with gathering the information. Despite our good preparation and sampling, we saw that there small details were forgotten. This details where not found with doing the sample. Probably, because we checked our tagging scheme with easy examples. In the real case, some facts where easy to find and other not. We didn't made an agreement how long we did search to any tweets for some fact. Fortunately, we where together when we started with the information gathering, so we could quickly make an appointment here.
After the information gathering, we analysed this information. Since our good preparation and making a well defined tagging scheme, the information analyse wasn't very hard. An advantage was that many of the facts were really objective and lightly interpretation sensitive. Almost all facts where based on numbers, like "10 people died in the disaster of Duisberg". This made the analyse easier.
We described in the method how to become to a conclusion. By take the sum of all tweets and divided this by the amount of true tweets, we get a rating. With this rating with decided if social media is quiet reliable, reliable or not reliable. After we did this, we found that this was not quite representative, because for some facts we didn't find any tweets and for some facts we find not enough tweets. Since it isn't realistic to simply count all tweets and divide by true, false or neutral statements to get a result, we decided to made a weighting for this. The facts were we find enough tweets weights more than the facts were couldn't find enough tweets. By this weighting we came to a representative conclusion.
Summary
Trough out the course we tried to work hard. This course is one of the two courses we have to follow until we can graduate. So the motivation is high. Using a good preparation we started too work to together on this subject. The combination of working hard and using a structured approach resulted into no serious problems and a good end result. During the research process with the problems we have incountered we altered the approach. This has resulted in structured approach to determine wheter social media is as reliable or not. After this research we can conclude that is the case.
| And what about the real research project? I thought this chapter should be about the content of your document and not about the research process. | |
|
| Jodocus Deunk → Onderzoeksmethoden 2 | Remove this comment when resolved! | |
References
- ↑ Kelly, Ryan, ed (August 12, 2009). "Twitter Study – August 2009" (PDF). Twitter Study Reveals Interesting Results About Usage. San Antonio, Texas: Pear Analytics. http://www.pearanalytics.com/blog/wp-content/uploads/2010/05/Twitter-Study-August-2009.pdf. Retrieved Jun 3, 2010