Onderzoeksmethoden 2/het werk/2008-9/Groep03
Task Solving Tactics
Onderzoeksmethoden 2, 2008
Boudewijn Geijtenbeek, Chiel Schutter, Dirk van der Linden, Freek van Workum
Onderwijsinstituut voor Informatica en Informatiekunde
Radboud Universiteit Nijmegen
version 18 februari 2022
Inhoud
Introduction
When presented with multiple problems or questions to solve in a limited amount of time there are several common strategies to start. Most people maintain some kind of tactic that can be described as sequential or prioritized problem solving. Sequential solvers work through the presented problems in a linear fashion, getting as far as they can and stopping when the time is up, no matter whether all problems have been solved or whether the solutions are satisfactory. Prioritized solving is based partially on the gut feeling of the solver and depends on his knowledge and experience to estimate how much time each problem will cost and what kind of problems would present itself, and prioritizing them in a way as to solve either as much as problems as possible, or as much complex or most needed problems as possible. For the sake of keeping time investment and experimental preparation and setup manageable we will not generate cases that would benefit from parallel solving approaches, which is essentially a more nuanced form of this where a person is aware of all problems and works through all of them at the same time, for instance by devising some kind of standardized amount of steps and executing a step for every problem before moving on to the next stop.
Problem statement
When presented with a set of n modeling tasks that range in complexity and a set amount of time to solve them in (where the time is generally not enough to solve all problems regardless of the tactic), what kind of tactic is most commonly undertaken and which tactic yields most useful results?
Theoretical framework
Conceptual model
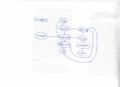
Initial conceptual model

ORM sketch of said model

Digitally rendered ORM version



Elements
R: CS/IS major students
O: ORM testcases
S: ORM testcases solutions
Variables
- Difficulty
- O -> Di
- Difficultylevel ∈ {1,2,3,4,5}
- Ordinal
- Tactic
- R -> O -> Ta
- Dominant tactic used on an ORM testcase ∈ {sequential,prioritized}
- Nominal
- Time
- R -> O -> Ti
- Time in minutes used on an ORM testcase ∈ Parsen mislukt (MathML met SVG- of PNG-terugval (aanbevolen voor moderne browsers en toegankelijkheidshulpmiddelen): Ongeldig antwoord ("Math extension cannot connect to Restbase.") van server "https://en.wikipedia.org/api/rest_v1/":): {\displaystyle \mathbb{N}} 0
- Ratio
- Similarity
- R -> O -> S -> Si
- Similarity[1] in percentage between solution and expected result ∈ Parsen mislukt (MathML met SVG- of PNG-terugval (aanbevolen voor moderne browsers en toegankelijkheidshulpmiddelen): Ongeldig antwoord ("Math extension cannot connect to Restbase.") van server "https://en.wikipedia.org/api/rest_v1/":): {\displaystyle \mathbb{N}} 0
- ?
Method
The setup of the TAP-sessions will be as following;
- Each individual is presented with several (small) cases which require a (semi-)formal model to be made in ORM.
- The individuals will be selected from a population which has experience with modeling cases in ORM (i.e. CS/IS majors)
- Each case varies in complexity, from trivial, to more complex, to downright paradoxical, but never in a set order (i.e. in no two experiments is the initial ordering of the cases exactly the same).
- Each case is modeled beforehand, and a most fitting model is saved as a comparison measure for the ones produced during the experiment.
- The individual is told to solve the problems in whatever way the want within the time span of 10 minutes.
- Beforehand they are instructed to verbalize their thoughts and other such things which are necessary for successful registration of the experiment.
- No help from the outside is allowed, nor are the observers to interact when an individual seems stalled, as this would be influencing the outcome of the experiment (i.e. an individual who gets stuck on a paradoxical case whilst using serial solving should not be actually told by the observer to move on)
- Each session (individual, multiple cases) is recorded by means of video and audio registration.
- Each session is processed and tagged according to a previously agreed upon tagging scheme.
- Each tagged session is analysed and given "scores" for the possible tactics that were used, and how successful the attempt was. The tags to be used are as following:
- [sequential]: subject displays a sequential approach to handling the cases
- [prioritized]: subject displays a prioritized approach to handling the cases
- [case-switch]: subject switches to new case
- [analysis]: subject spends time analysing a case
- Conclusions are drawn about the most used methods (by which thought processes they were chosen), and how effective these methods were (by comparison to the expected models).
Results
Data
| Due to privacy reasons raw data of the TAP sessions is only available upon request as digital video encoded in H264/AAC. | ||||||||||||||
| Subject 1, case-order = 4,3,1,2,5 | Subject 2, case-order = 3,2,4,5,1 | Subject 3, case-order = 2,5,3,4,1 | Subject 4, case-order = 1,2,3,4,5 | Subject 5, case-order = 1,3,5,2,4 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|

|

|

|

|

| ||||||||||
|
|
|
|
| ||||||||||
|
|
|
|
| ||||||||||












Analysis
The raw data above was quantified as much as possible and processed with the help of an analysis spreadsheet which gave the following results. The spreadsheet used for this can be downloaded in the addendum.
| Subject | Case score | Time per case | Amount of tags |
|---|---|---|---|
| Subject 1 |
|
|
|
| Subject 2 |
|
|
|
| Subject 3 |
|
|
|
| Subject 4 |
|
|
|
| Subject 5 |
|
|
|
| cn = score in percentage for case n C = cumulative score |
cn = time taken for case n in seconds C = total time taken |
Conclusion
In the analysis two subjects used a prioritized approach, of which one subject solely prioritized by skipping cases he seemed to take too much time in, and one analysed all the cases beforehand and decided on an order in which to model them. The remaining three subjects all used a sequential approach where the cases were modeled in the order as given, with little to no looking forward or prioritizing based on how much was left to do in the given (little) time.
Although the overall case scores for subjects who used a prioritized approach is lower than those who approached the cases sequentially our experiment is both too little to yield (statistically) significant data to draw conclusions from. We also cannot rule out the possibility that other factors contributed to the score. This means that we cannot give a useful answer to the first part of our problem statement without expanding the size of the experiment. In our analysis no single tactic (prioritized, sequential) was used significantly more than another (3 uses of sequential vs. 2 uses of prioritized). While in our analysis both the overal score, and detailed scores that can be seen in the analysis spreadsheet seemed to be higher for those subjects who used a sequential approach we cannot conclude anything useful from this, as the experiment is still too small to give significant statistical underpinnings, and we cannot rule out other factors contributing to the score differences (i.e. innate modeling skill of each subject, uncontrolled environmental factors).
There are, however, some lessons we can draw from our experiment and the analysis we have that indicate some interesting points. First, the majority of the subjects seemed unfazed by the time pressure placed on them, which can mean either the experimental setup was not stressful enough to invoke time-stress related responses, or most subjects from the population we used (CS/IS graduate students) are already thoroughly used to working in (time-related) stressful situations.
Furthermore, the detailed case scores in the analysis spreadsheet show that generally subjects were very capable in distilling the abstract concepts out of the stakeholder texts, but were less succesful in abstracting the fact types and constraints. This gives some hints for further experiments to more explicitely focus on how subjects build relations between concepts in their mind during the modeling process.
It also seems a likely possibility that a high ratio of spending time analysing cases to actually modeling them might be counterproductive. While the experimental setup was too small to give definitive answers here, future research might also focus on whether this detailed analysis beforehand yields lower case scores than "model and improve as you go" methods where the subject just starts creating models and alters them to fit new insights them in a later stage.
References / Notes
- ↑ Similarity is computed by comparing the total objects (i.e. roles, facttypes) and properties (i.e. constraints) in the solution to the ones (explicitly) described in the testcase. From this a similarity score is is derived by calculating the amount of objects/properties divided by the amount of objects/properties in the testcase. Scores of < 0 are assumed not to appear, and any score of > 1 is treated as a score of 1 for the purposes of this research.
- ↑ If the given time is retroactively decreased to 10 minutes, given the subject would have continued with the same method which is very likely, C' would be the percentagewise score instead of C.
- ↑ After this session we decided to decrease total time down to 10 minutes to make sure not every case could be easily finished. This is taken into account in the conclusion as we only look at the overall tagging of this case, and for statistics purposes disregard work done after C=600. As the subject in this case worked purely sequential we think this will not negatively influence the quality of our analysis by too great a factor.
4. The scores in this spreadsheet are given by counting whether each concept, fact type and constraint that was expected appears by filling in a "1" for something that was included in the subject's solution, and a "0" for something that was not included. From this a similarity score in % is calculated for each rough "type" of model objects (i.e. concepts, fact types, constraints/complex structures), for the entire model, and for the entirety of the experiment.
Addendum
ORM testcase descriptions
| nr. | description |
|---|---|
| 1 | Description of a very simple case with no constraints or complex structures like sub/super elements etc (i.e. a system where people can place orders and the orders can be looked up with what they consist of and what date they were placed at) |
| 2 | Description of a simple case with a (minimal) amount of constraints |
| 3 | Description of a normal case with a couple of constraints and at least one complex structure like sub/super elements |
| 4 | Description of a hard case with multiple constraints, multiple complex structures |
| 5 | Description of a very hard case with multiple (conflicting) constraints, multiple complex structures that might not lead to meaningful model |
ORM testcase stakeholder texts
| nr. | full text |
|---|---|
| 1 | When a customer comes to us to order an object we record their name. Then we file an order (with an unique ID) with the date the order has been issued (it's possible we process orders that have been issued days before) and in the order of course is listed which objects are ordered, we only write down the IDs of the object since our stock is based upon those IDs. |
| 2 | Our hospital utilizes a very common way of registering a patient admission. We have different departments with unique names, like IC and Neurology. When a patient is admitted they are assigned an unique number. Throughout the processes in the hospital this number is primary utilized. When a patient is admitted we record their number, date of admission and to which department they are admitted. In our hospital it's possible that a patient is admitted multiple times on a certain day. |
| 3 | Ons afstandsleerinstituut biedt digitale toetsing aan, bestaande uit drie toetssoorten. We hebben oefentoetsen, mondelinge (per telefoon of voice chat) overhoringen, en officiele tentamens. Deze drie zien we allemaal als een vorm van toets. Alle toetsen leveren een cijfer op, maar alleen de cijfers van mondelinge overhoringen en officiele tentamens leveren studiekrediet op. Een gebruiker van ons toetssysteem wordt met de standaardinformatie geidentificeerd, naam en toenaam, welke opleiding ze doen enzovoort. Overigens bestaat een oefentoets uit een bepaald aantal vragen die willekeurig geselecteerd worden uit de totale verzameling vragen. Zo'n toets, of verzameling vragen, moet wel uniek zijn, we wille niet een bepaalde toets meer dan een keer aan iemand voorleggen natuurlijk. Die vragen hebben ook allemaal een bepaalde moeilijkheid, zeg met iets numerieks als van 1 tot en met 5. |
| 4 | I run a small webshop which sells stuffed animals. Recently I've started selling heffalumps and woozles, which complicated matters a bit as there are so many kinds my webshop can't handle them. I need an extension to my system which can at least differentiate that a heffalump is a woozle is very confusle, as well that a heffalump is a woozle's very sly, sly, sly. They come in pairs of one, are either black or brown, big or small, quick and slick or insincere. |
| 5 | This musical association is divided into four unique self-operating sub-associations: a marching band, an orchestra, a drumline, majorettes. A member of our association can only be a part of one of the sub-associations at a time. The sub-associations each have their own type of performances. The orchestra is the exception whereas it only does (live) concerts on a certain day. The marching band performs in the form of marching, which also is done on a certain day. The drumline, majorettes and the marchingband occasionally collaborate in show performances on a certain day where it is possible that they perform in any combination possible (just majorettes, drumline or marching band or a combination of those three, or all three at once). Then there is the board that runs our musical association. The board consists of five standard functions which are: chairman, secretary (the secretary can arrange any performance for any sub-association), treasurer and three general members and acts for a specific period. Any member of our musical association can be in the board, but only execute one function at a time. |
ORM testcase solutions
| nr. | elements (identifier) | facttypes | complex structures |
|---|---|---|---|
| 1 | Customer (Name), Order (Id), Orderedobject (Id), Orderdate (Date) | Customer-[]-Order, Order-[]-Orderedobject, Order-[]-Orderdate | / |
| 2 | Patient (Number), Day (Date), Department (Name) | Patient-[Admission]-Day-[Admission]-Department | UC on Patient (Number), Day (Date) and Department (name). TC on Day (Date) |
| 3 | Toets (Id), Vraag (Id), Oefentoets (Id), Mondelinge overhoring (Id), Tentamen (Id), Cijfer (Nr), Studiekrediet (Nr), Gebruiker (Id), Gebruikersnaam (Naam), Opleiding (Naam), Moeilijkheid ∈ {1,2,3,4,5} | Toets (Id)-[bestaat uit]-Vraag, Toets (Id)-[gemaakt door]-Gebruiker (Id)-[heeft cijfer]-Cijfer (Nr), Toets (Id)-[levert op aan ec's]-Studiekrediet (Nr), Gebruiker (Id)-[heeft studiekrediet]-Studiekrediet (Nr), Gebruiker (Id)-[heeft gebruikersnaam]-Gebruikersnaam (Naam), Gebruiker (Id)-[heeft opleiding]-Opleiding (Naam) | Toets (Id) is verzameling van >= 1 Vraag (Id), Oefentoets (Id) -> Toets (Id), Mondelinge overhoring (Id) -> Toets (Id), Tentamen (Id) -> Toets (Id), UC over Toets (Id)-[gemaakt door]-Gebruiker (Id)-[heeft cijfer]-Cijfer (Nr), UC op Gebruiker (Id)-[heeft opleiding], UC op Gebruiker (Id)-[heeft studiekrediet], UC op Gebruiker (Id)-[heeft opleiding], TC op Toets (Id)-[bestaat uit], TC op Gebruiker (Id)-[heeft gebruikersnaam], TC op Gebruiker (Id)-[heeft opleiding], TC op Gebruiker (Id)-[heeft studiekrediet] |
| 4 | Stuffed Animal (Kind), Heffalump (Id), Woozle (Id), Color ∈ {Black, Brown}, Size ∈ {Big, Small}, Property ∈ {Quick and slick, Insincere} | Stuffed Animal (Kind), Heffalump -> Stuffed Animal (Kind), Woozle -> Stuffed Animal (Kind), Heffalump -> Woozle, Woozle-[is confusle], Woozle-[is very sly], Woozle-[has color]-Color, Woozle-[has size]-Size, Woozle-[has property]-Property | Heffalump -> Stuffed Animal (Kind), Woozle -> Stuffed Animal (Kind), Heffalump -> Woozle, UC on Woozle-[has property], Woozle-[has size], Woozle-[has color], Woozle-[is confusle], Woozle-[is very sly], TC on Woozle-[has property] |
| 5 | Member (Name), Day (Date), Period (Date-Date), Musical association, Marching band, Orchestra, Drumline, Majorettes, Performance, Marching, Concert, Show, Board, Chairman, Secretary, Treasurer, General member (I), General member (II), General member (III) | Member-[is member of]-Marching band, Member-[is member of]-Orchestra, Member-[is member of]-Drumline, Member-[is member of]-Majorettes, Member-[is boardmember as ...]-Chairman, Member-[is boardmember as ...]-Secretary, Member-[is boardmember as ...]-Treasurer, Member-[is boardmember as ...]-General member (I), Member-[is boardmember as ...]-General member (II), Member-[is boardmember as ...]-General member (III), Marching band-[performes]-Day-[performes]-Marching, Orchestra-[performes]-Day-[performes]-Concert, (Marching band, Drumline, Majorettes)-[performes]-Day-[performes]-Show | Musical association <--- Marching band, Musical association <--- Orchestra, Musical association <--- Drumline, Musical association <--- Majorettes, Performance <--- Marching, Performance <--- Concert, Performance <--- Show, Board <--- Chairman, Board <--- Secretary, Board <--- Treasurer, Board <--- General member (I), Board <--- General member (II), Board <--- General member (III), XC on Member-[is member of]-(Marching band, Orchestra, Drumline, Majorettes), XC on Member[is boardmember as ..]-(Chairman, Secretary, Treasurer, General member (I), General member (II), General member (III)), and an initial number of 7 TC's and 13 UC's |
ORM testcase solution models
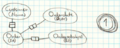
Case 1
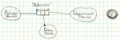
Case 2

Case 3
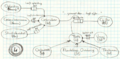
Case 4
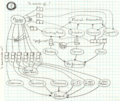
Case 5


